3. Verbesserung der Interoperabilität
Praktische Interoperabilität (workable interoperability) kann letztendlich nur an laufenden Systemen/Anwendungen demonstriert werden. Dazu müssen (fertig) entwickelte Schnittstellen zum Einsatz kommen. Auf der Zeitachse der Prozessschritte ist das also der letzte:
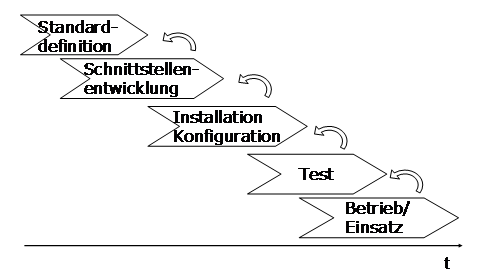
Abbildung 1: Zeitachse
Bis dahin gibt es mehrere Möglichkeiten, die Interoperabilität überhaupt zu ermöglichen und darauf aufbauend zu verbessern. Diese Verbesserung der Interoperabilität kann dabei auf verschiedene Arten erreicht werden, die sich gegenseitig ergänzen. Neben der primären zeitlichen Achse ist der genutzte Standard für das Einbringen von Verbesserungen essentiell. Je früher und je präziser die Standardisierung vorgenommen wird, desto effektiver sind die Maßnahmen. Dazwischen lassen sich die einzelnen Maßnahmen entsprechend unterteilen/klassifizieren.
Die nachfolgend aufgelisteten Verbesserungen werden dem entsprechend eingeordnet.
3.1. v2.x-Publishing
Während der Weiterentwicklung der Versionen der 2er Familie hat sich herausgestellt, dass die Spezifikation des Standards über ein Textverarbeitungsprogramm [SchoOem2001] problematisch ist. Die erste bekannte Version 2.1 wurde in einer Fassung ausgeliefert, die nicht einmal brauchbar zu drucken war, da die Formatierung an das amerikanische US-Letter-Format angepasst war und für das deutsche DIN/A4-Format zu breit ist. Infolgedessen wurden "tabellenorientierte" Information unleserlich umgebrochen. In der Folgeversion v2.2 wurde dieses Manko zwar beseitigt, dennoch gab es genügend Anlass Fragen zu stellen. Ausgelöst wurde dies insbesondere durch Inkonsistenzen innerhalb der Dokumente. Zu allem Überfluss sorgte ein per Hand zusammengestellter Anhang für Verwirrung. Diese Probleme haben bereits 1993 in Deutschland mit zur Gründung des ersten technischen Komitees innerhalb der Benutzergruppe beigetragen, um eine zentrale Anlaufstelle zur Klärung Fragen dieser Art zu bilden.
Im Laufe späterer Entwicklungen wurden beide Probleme angegangen. Die Basis bildet die sog. "HL7 comprehensive database" [OemDud1996, OemSto2000], die die relevanten Informationen des Standards enthält. Der Anhang wird jetzt aus den extrahierten und in der Datenbank gespeicherten Daten generiert. Damit ist der Anhang zumindest mit den eigentlichen Kapiteln konsistent.
Es bleibt hierbei die Fragestellung, ob die Datenbank selbst mit dem Standard hundertprozentig übereinstimmt? Da man aus inkonsistenten Informationen keine Datenbank mit relationaler Integrität füllen kann, muss dies verneint werden.
Beim Extrahieren der Daten für die Datenbank aus dem eigentlichen Standard müssen diese Inkonsistenzen identifiziert und aufgelöst werden. Dabei dient die hieraus erstellte Liste als Basis für Vorschläge (Proposals) zur Weiterentwicklung der nächsten Version. Leider lassen sich aus Kompatibilitätsgründen viele dieser Verbesserungen nicht direkt umsetzen, da sie Fragestellungen adressieren, deren Lösung in der bisherigen inkonsistenten Weise bereits akzeptiert worden ist.
Es bleibt das Problem, dass unterschiedliche Komitees die Kapitel weiterführen, ohne genau über Änderungen in anderen Kapiteln informiert zu werden. Ein Styleguide [OemVei2000] kann sich teilweise dieses Problems annehmen. Direkt sorgt er für klare Vorgaben, welche Formatierungen wann anzuwenden sind. Indirekt sind mit diesen Vorgaben aber semantische Inhalte (Zuordnung von Metadaten) verbunden. Nun lässt sich zwar nicht garantieren, dass die Editoren sich an diese Vorgaben halten, ein halbautomatischer Prozess kann aber die eingegebenen Informationen (Absätze, Überschriften, Tabellen) extrahieren und in einer Zwischendatenbank ablegen. Letztere ermöglicht dann Konsistenzprüfungen. Beispielsweise, ob alle genutzten Tabellen auch tatsächlich definiert worden sind oder ob Längenangaben einheitlich sind. Darüber hinaus können auch semantische Inhalte verifiziert werden. So zum Beispiel ob Felder vom Datentyp CNE nur in Kombination mit HL7-definierten Tabellen genutzt werden. Alle derartigen Informationen lassen sich während des Ballotprozesses als negative Kommentare einbringen und führen so zu einer Verbesserung des Standards insgesamt.
3.2. Die HL7-Datenbank
In der ersten Fassung wurde die HL7-Datenbank nur genutzt, um die HL7 Version 2.1 konsistent zu bekommen. Gleichzeitig wurde in Deutschland mit der Interpretation des Standards begonnen. Zeitgleich erschien die Version 2.2 in den USA.
Beides wurde zum Anlass genommen, die HL7-Datenbank zu erweitern. Im Zuge weiterer Entwicklungsschritte umfasst diese Datenbank eine ansehnliche Liste von Eigenschaften, die zur Konsistenzsicherung des Standards und auch für Werkzeug-/Schnittstellenentwicklungen größerer und kleinerer Hersteller genutzt werden:
- variantenfähig
- webfähig mittels PHP
- mehrsprachig
- enthält alle Metadaten
- enthält kompletten Standard (Extrakt der Word-Dokumente)
- Generatorfunktionen (HTML und XML-Schema sowie - mit dieser Arbeit - OWL)
- Vergleichsfunktionen
- Erweiterbarkeit
Derzeit wird überlegt, ob man diese Datenbank nicht zur Grundlage der zukünftigen Entwicklungen des Standards selbst macht.
Außerdem laufen die ersten Arbeiten, um diese Datenbank zu einer Multi-Standards-Database weiter zu entwickeln, in der neben HL7 v2.x auch IHE und DICOM enthalten sind. Hierzu sind die entsprechenden Metamodelle zu erarbeiten und die Dokumentationen der Standards durch Etablierung von weiteren Styleguides darauf vorzubereiten. Letzteres setzt eine intensive Zusammenarbeit mit den diversen Komitees und den einzelnen Editoren voraus.
Mit dieser Erweiterung ließen sich auch übergreifende Konsistenz- und Integrationsprüfungen vornehmen.
Füllen der Datenbank mit Werten
Ein nicht unerhebliches Problem stellt das Befüllen der Datenbank mit Werten dar, d.h. die Fragestellung, wie die vielen Einzelsätze konsistent erzeugt werden können. Im Laufe der Arbeit wurden verschiedene Ansätze überprüft und für nicht brauchbar bzw. funktional nicht ausreichend befunden, obwohl sie Ergebnisse geliefert haben. Ein mehrfaches Redesign der Vorgehensweise wurde nicht zuletzt auch durch die Erhöhung der Komplexität und Umfang des Standards selbst verursacht, so dass der manuelle Zusatzaufwand auf ein Minimum reduziert werden muss.
Aufgrund der Inkonsistenz im Standard selber sind mindestens drei Schritte notwendig:
- a) Extraktion der Daten aus den Word-Dokumenten
- b) Herstellung der Datenkonsistenz
- c) Übertragen der Daten in die Datenbank
Der Punkt b) ist eine reine Fleißarbeit, um die gewonnenen Daten mit den Originaldokumenten abzugleichen. Dabei ist die eigentliche Intention der konfliktbehafteteten Daten herauszuarbeiten, um die inkonsistenten Daten entsprechend korrigieren zu können. Letzteres führt automatisch zu einer Fehlerliste, die im Ballotverfahren die Grundlage für Kommentare ist. Der letzte Schritt - das Hochladen der Daten in die endgültige Datenbank - kann dann automatisch geschehen, da die Daten schon in einer strukturierten Form vorliegen.
Die eigentliche Schwierigkeit besteht darin, auf die Daten in den Word-Dokumenten effizient zugreifen zu können. Dabei haben sich folgende Varianten ergeben:
| Variante | Verfahren | Bewertung |
| 1 | Speichern der Dokumente direkt im HTML-Format mit manueller Übertragung der Daten inkl. der HTML-Links | sehr hoher manueller Aufwand; keine gesicherte Integration in Form von Links |
| 2 | Extraktion der Daten aus den Tabellen via VBA-Makros; separate Speicherung als HTML-Dokumente | Voraussetzung ist Einhaltung eines Styleguides; manuelle Zusammenführung der Links aus der HTML-Fassung in die Datenbank |
| 3 | Speichern der Dokumente als XML und Auswertung der Daten auf Basis der Formatvorlagen | Voraussetzung ist Einhaltung eines Styleguides; automatische Generierung der HTML-Fassung mit korrekten Links; alle Dateninterpretationen müssen in einem Single-Step-Ansatz während des Parsens ermittelt werden |
| 4 | Extraktion aller Daten (Absätze) durch ein Programm; Bewertung der Daten durch ein zweites Programm | Trennung der Datenbeschaffung von der Interpretation; Multi-Step-Approach; leichtere Erweiterbarkeit auf andere Standards |
Tabelle 1: Alternativen zum Füllen der Datenbank mit Werten
3.3. Alternativen zum Füllen der Datenbank mit Werten
Der hohe Aufwand, der auch insbesondere die Editoren des Standards herausfordert, begründet die Suche nach Alternativen. Der wohl einfachste Weg ist das direkte Erarbeiten des Standards auf Basis einer Datenbank. Hierbei müssen dann zusätzliche Werkzeuge zum Einsatz kommen, die ein komfortables Editieren erlauben. Dabei gilt es zusätzliche Anforderungen zu erfüllen:
- Texteditorfunktionalität mit Copy und Paste
- Revision-Marks (Erkennen und Darstellen von Änderungen)
- automatische Nummerierung der Absätze
- Sperrung von Bereichen, die direkt erstellt werden, wie bspw. Segmenttabellen, Datenelemente und Datentypen
- Referenzierung (bspw. nur Verwendung von bereits definierte Datenelementen)
- Replikation der Datenbank mit der anderer Editoren bzw. Online-Zugriff auf eine zentrale Datenbank
- ....
Ein erster lauffähiger Ansatz wurde 2001 auf der IHIC in Reading vorgestellt: [SchoOem2001]
3.4. Dokumentation der Schnittstelle
Der wichtigste Schritt für eine erfolgreiche Interoperabilität ist eine gute Dokumentation der implementierten Schnittstelle. Leider muss festgehalten werden, dass die meisten Hersteller nicht über eine solche verfügen. Wenn Sie überhaupt eine schriftliche Dokumentation vorweisen können, so handelt es sich in vielen Fällen um eine Kopie/Extraktion des Standards.
Um in Fehlerfällen eine Klärung erreichen zu können, ist ein genaues Verständnis des Systemverhaltens unerlässlich. Deshalb gilt es, die Dokumentation um weitere Informationen anzureichern. Nicht zuletzt hat der Kunde ein Anrecht auf eine vollständige und korrekte Dokumentation. Eine Schwierigkeit besteht allerdings auch darin, die im "Customizing" versteckten Konfigurationsdetails entsprechend umzusetzen.
Die nachfolgende Grafik [Sing2003, SinJuu2001] veranschaulicht, dass man durch genaues Verstehen des Schnittstellenverhaltens und einer geeigneten Dokumentation bereits sehr viel für eine Umstellung von HL7 v2.x auf V3 vorbereiten kann.
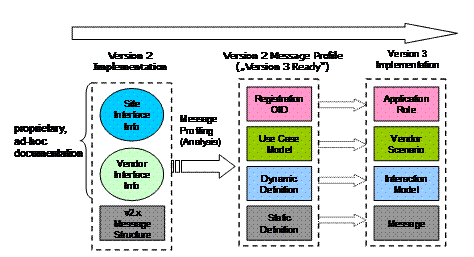
Abbildung 3: Migration HL7 v2.x -> V3
Die in der HL7 Version 2 vorgegebenen Nachrichten verlangen zusätzliche Informationen, die relativ "statisch" umgesetzt werden. Dazu gehören bspw. Restriktionen der Feldlängen, von Rekursionen, die Interpretation von Segmentinhalten oder das Vorhandensein von Vor- und Nachbedingungen für eine Nachricht. Im Falle der Nutzung einer Schnittstelle kommen noch weitere Einschränkungen hinzu wie bspw. die Festlegung auf bestimmte Kataloge, die umgekehrt nicht komplett wiedergegeben, sondern nur referenziert werden sollten.
Bei genauer Betrachtung decken sich diese Informationen mit den statischen und dynamischen Definitionen sowie den diversen Szenarien im V3 Standard.
Das Problem der Dokumentation wird mit dem sog.
Proposal #605,
das in der Proposal Database hinterlegt worden ist und derzeit in einer mehrfach
verbesserten Form (v07)
zur Umsetzung mit der Version 2.8 vorbereitet wird.
Das ECCF (Enterprise Conformance and Compliance Framework) des
SAEAF (Services Aware Enterprise Architecture Framework)
greift diesen Vorschlag auf.
3.4.1 Nachrichtenprofile
Nachrichtenprofile bilden eine Hierarchie dar, d.h. ein Profil baut auf einem anderen auf. Hierbei gilt es gewisse Regeln zu beachten. So dürfen in dieser Ableitungshierarchie nur Einschränkungen vorgenommen werden. Wenn bspw. ein Element (z.B. Feld) in einem Profil "Required" ist, so darf es in der Ableitung nicht wieder auf "optional" oder sogar "nicht erlaubt" gesetzt werden. (Die möglichen Übergänge sind in Kapitel 2 von HL7 v2.x erläutert.)
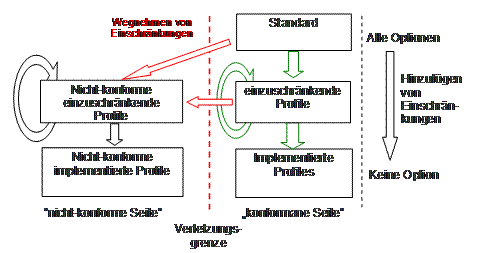
Abbildung 4: Ableitung Profilhierarchie
Nachfolgend 2 Beispiele für eine solche Hierarchie. Im ersten Beispiel gibt es eine nationale Vorgabe, auf der dann eine Krankenhauskette einen Hausstandard fordert, der dann von einem Hersteller umgesetzt wird. Im Beispiel 2 baut ein Hersteller auf der nationalen Vorgabe in generischer Form auf, d.h. in einem konkreten Einsatz kann das noch einmal gezielt verfeinert/ eingeschränkt werden:
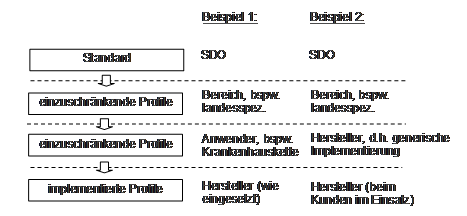
Abbildung 5: Profilhierarchiebeispiele
Diese Beispiele lassen sich aber auch miteinander kombinieren und beliebig tief schachteln.
3.4.2 Konformanzprüfung
Ziel muss es letztendlich sein, dass zwei Implementierungen zueinander kompatibel sind,
daher kann aus der vorhergehenden Darstellung die letzte Ebene genommen werden, in der
zwei Implementierungen gegeneinander geprüft werden.
Im einfachsten Fall kann dieser Test "live" erfolgen, d.h. zwei Systeme werden direkt gegeneinander
getestet, wie es bspw. bei dem IHE Connect-a-thon (s.u.) der Fall ist. Für ein Krankenhaus ist
dies aber nur bedingt möglich, da z.T durch konkrete Implementierungen oder nicht erfolgte
Vorgaben Abweichungen vorliegen. Im Prinzip möchte man wissen, ob ein System Daten mit einem
anderen austauschen kann?!
Eine allgemeine Aussage a la "das System kann HL7" kann wie aus den vorangehenden Erläuterungen
ersichtlich ist nicht als zuverlässig betrachtet werden.
Eine Aussage wie "das System ist kompliant zu der Vorgabe" aber auch nicht, da jedes System für
sich weitere Einschränkungen vorgenommen haben kann. So könnte bspw. ein Feld zusätzlich auf
"Required" gesetzt sein. Das ist nicht weiter tragisch, solange dieses System nicht als Empfänger
von Daten eingesetzt wird und die jeweiligen sendenden Systeme diese Information nicht mit übertragen.
Um Den Test von zwei Systemen im Echteinsatz (5) zu ersetzen, muss eine Alternative gesucht werden: (6). Dies funktioniert unter ein paar Bedingungen: (Zum Thema Zertifizierung s.u.)
- Die Hersteller haben eine derartige Dokumentation. Dies kann durch das Krankenhaus im Rahmen einer Forderung aber realisiert werden.
- Die Dokumentation für die Schnittstelle entspricht der eingesetzten Software. Dies kann ebenfalls vom Krankenhaus als Bestandteil des Kaufvertrages eingefordert werden.
- Die Dokumentation entspricht der Vorgabe durch das Krankenhaus. Dies kann manuell - oder bei höherem Qualitätsniveau sogar automatisch - geprüft werden.
- Die beiden Dokumentationen sind zueinander kompatibel: Dies kann ebenfalls in der Eigenschaft als sendendes bzw. empfangendes System geprüft werden.
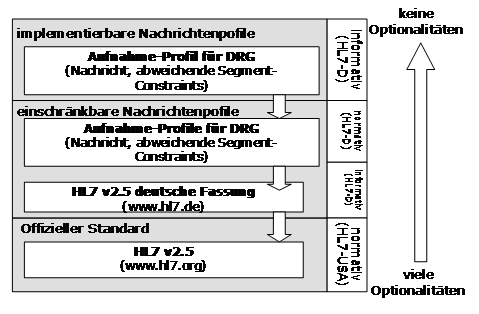
Abbildung 6: mögliche Prüfungen zwischen Systemen und Dokumentationen
| Documentation | Implementation | ||
| components | constrainable profile | implementable profile | |
| A | X | ||
| B | X | ||
| C | X | ||
| D | X | ||
| E | X | ||
| F | X | ||
Je nach dem, ob man eine Implementierung gegen eine Vorgabe (Dokument), eine Dokumentation gegen eine Vorgabe oder zwei Dokumentationen bzw. Implementierungen gegeneinander testet, spricht man von Konformanz, Compliance oder Kompatibilität:
| Arrow | Linkage | conformance | compliance | compatibility |
| 0 | A - B | X | ||
| 1 | B - C | X | ||
| 2 | B - D | X | ||
| 3 | B - E | X | ||
| 4 | B - F | X | ||
| 5 | C - E | X | ||
| 6 | D - F | X | ||
| 7 | C - D | X | ||
| 8 | E - F | X |
3.4.3 "Documentation Quality Hierarchy"
Das bereits erwähnte Proposal #605 definiert verschiedene Qualitätskriterien, die aufeinander aufbauend eine Hierarchie bilden. Um mit der Dokumentation auf eine höhere Qualitätsstufe zu kommen, sind höhere Anforderungen zu erfüllen. Nachfolgend die Erläuterungen dazu aus Proposal #605:
| Documentation Quality | Description | Consequences |
| 0 | A vendor claims conformance to HL7, but has no proof of his claim. Note: This level can be treated as the "standard conformance" as all vendors claim conformance to HL7 per se. | none |
| 1 | A vendor can proof his claim by a documentation of his interface. The format and the contents of this documentation do not matter.Note: Most probably a vendor will copy paragraphs from the original standard which is allowed on this level. | Vendor must provide a document. |
| 2 | The documentation he provides fulfils the requirements of a conformance profile as listed in chapter 2B. | Vendor must provide a conformance statement as defined in chapter 2B. |
| 3 | The documentation is machine processable. Note: One option is to use the MWB to create this file. But other tools are acceptable as well. | The vendor has to provide a computable (constrainable) conformance profile file as defined in chapter 2B. |
| 4 | The documentation is a conformance profile fulfilling the criteria for implementable profiles, i.e. no options are allowed any more. Note: the criteria listed for level 3 allows a test to verify that the profile fulfils the requirements for implementable profiles. | Vendor must provide a file which fulfils the requirements for implementable conformance profile as defined in chapter 2B. |
| 5 | The profile is (successfully) tested against another profile. (This will cause some problems if there is no standard where we can test against. Perhaps we can use the MWB standard libraries, but those are based on the HL7 database.) Note: This testing is done against a higher level (=less constraint) profile, probably a constrainable profile issued either by a vendor, affiliate or HQ itself. Therefore, this testing is done vertically and checks whether the provided profile only add additional constraints.. | Requires references to the profiles tested against. Furthermore, the results of the tests must be stated. Furthermore, the means and details of this testing must be specified. As a consequence, it will become obvious, whether the relationship to the underlying profile is "conformant" or "conflicting". |
| 6 | Another option of testing is horizontally. This way, two (implementable) profiles are tested with a sender/receiver perspective. One profile takes the role of the sender, the other of the receiver. It should be tested, whether this will result in interoperabability problems. Note: On this level we talk about "compatible" and "incompatible" profiles. | Requires references to the profiles tested against. Furthermore, the role must be mentioned. |
3.5. V3-Publishing
Im V3-Standard wurde dieses Problem recht frühzeitig angegangen und durch die sogenannte "Pubs-DB" ("Publishing Database") gelöst. Die Editoren sind aufgefordert, die Inhalte gemäß Anleitung (Facilitator Guide) entsprechend einzugeben.
Basis für die Tragfähigkeit dieses Konzeptes ist das Vorhandensein sog. Artefact-IDs. Hierunter sind eindeutige Identifikatoren für die verschiedenen Objekte (Application Roles, Interactions, Message Types, ..) zu verstehen, die eine eindeutige Referenzierung erlauben. Diese Artefact-IDs werden nach einem Algorithmus erzeugt, so dass die verschiedenen TCs unabhängig voneinander an einer Weiterentwicklung der Spezifikationen arbeiten können. Eine Referenzierung externer Objekte ist damit ebenfalls möglich.
Gemeinsam genutzte Informationen wie bspw. CMETs werden zyklisch an die TCs verteilt, so dass man einen gemeinsamen Arbeitsstand hat.
Jedes TC hat dabei seine eigene Pubs-DB. Zur Publizierung der Informationen werden die Datenbanken zusammengeführt und halbautomatisch verarbeitet, um daraus dann einen Gesamtpublikation zu erstellen.
In Zukunft wird aber von dieser Datenbank Abstand genommen, da man auf die sog. MIF-Files umsteigt, die auch die Grundlage für diese Arbeit sind.
3.6. Dokumentenorientierte Spezifikationen
Nicht alle Spezifikationen sind modellorientiert, sondern werden primär als Text erstellt. Beispiele sind die CDA- und das "Refinement, Conformance and Localisation"-Spezifikation. Solche Dokumente werden gemäß einem vorgegebenen Schema in XML erstellt und können so einem einheitlichen Publikationsprozess unterworfen werden.
Die Einbindung externer Objekte wie bspw. Grafiken erfolgt hier ebenfalls über die Artefact-IDs.
3.7. v2.x: Komponentenmodell für Datentypen
Bis zur Version 2.4 wurden Datentypen als simple Aneinanderreihung der Komponenten betrachtet. Hierbei wurde lediglich der Datentyp berücksichtigt.
Im Text - sowohl in der Beschreibung des Datentyps als auch des Feldes - gab es zusätzliche Informationen, die konkret einer Komponente zugeordnet werden mussten. Über das sog. Komponentenmodell, das mit der Version 2.5 offiziell eingeführt wurde, konnten die bisher nur im Text beschriebenen Zuordnungen explizit gemacht werden.
In der HL7-Datenbank wurde dieses Komponentenmodell bereits mit der Version 2.1 eingeführt, um die bereits vorhandenen Details korrekt abbilden zu können. (Ein Beispiel hierfür ist der Datentyp CM, der unterschiedliche Strukturen je nach Verwendung vorsah - was der semantischen Interoperabilität nicht unbedingt dienlich ist.)
Eine Schwierigkeit besteht darin, die diversen Eigenschaften den entsprechenden Elementen korrekt zuzuordnen, da es kein offizielles Metamodell für die 2er Versionen gibt. Die nachfolgende Tabelle versucht dies entsprechend wiederzugeben:
Bezug Aspekt | Feld | Datentyp | Komponente |
| Länge | (über Datentyp) | X (d.h. Gesamtlänge als Summe der Komponenten) | X |
| Datentyp | X | (über Komponenten) | X |
| Tabelle | X (bei einfachen Datentypen) | (über Komponenten) | X |
| Optionalität | X | - | X |
| wiederholbar | X | - | - |
| Anzahl Wiederholungen | X | - | - |
Tabelle 2: Zuordnung der Eigenschaften
3.8. v2.x: implizite Segmentstrukturen
Ein bereits angedeutetes Problem sind die vielen impliziten Informationsinhalte. Eine Implementierung des Standards wird erheblich vereinfacht, wenn diese Informationen auch explizit ersichtlich sind. In der nachfolgenden Nachrichtenstruktur sind die expliziten Informationsinhalte als "Single-Choice"-Elemente (grau hinterlegt) eingefügt. Dieses Ausdrucksmittel ist definitiv seit der ersten HL7-2er-Version im Standard enthalten, aber erst seit v2.3.1 explizit erwähnt. Leider haben die verschiedenen TCs die damit verbundenen Möglichkeiten weder erkannt noch umgesetzt:
| ADT^A24^ADT_A24 | ADT Message | Status | Chapter |
| MSH | Message Header | 2 | |
| [{ SFT }] | Software Segment | 2 | |
| [ UAC ] | User Authentication Credential | 2 | |
| EVN | Event Type | 3 | |
| < | PATIENT_1 | ||
| PID | Patient (1) Identification | 3 | |
| [ PD1 ] | Patient (1) Additional Demographics | 3 | |
| [ PV1 ] | Patient (1) Visit | 3 | |
| [{ DB1 }] | Patient (1) Disability Information | 3 | |
| > | PATIENT_1 | ||
| < | PATIENT_2 | ||
| PID | Patient (2) Identification | 3 | |
| [ PD1 ] | Patient (2) Additional Demographics | 3 | |
| [ PV1 ] | Patient (2) Visit | 3 | |
| [{ DB1 }] | Patient (2) Disability Information | 3 | |
| > | PATIENT_2 |
Tabelle 3: Nachrichtenstruktur "ADT^A24: Patient Link" mit expliziten Informationen
Im obigen Beispiel sind die beiden Segment-Sequenzen für die Identifikation der beiden Patienten identisch. Eine korrekte Zuordnung der Semantik lässt sich aber nur über die Reihenfolge/Position der Segmente in der Nachricht bestimmen. Dieses Problem führt in der XML-Kodierung zu zusätzlichen Schwierigkeiten, da die XPath-Ausdrücke identisch sind. In dem angeführten Beispiel lässt sich das evtl. noch durch Positionsangaben beheben, in anderen Beispielen aber nicht mehr.
Die grau markierten Zeilen geben den implizit vorhandenen Informationen einen expliziten Namen. In der XML-Kodierung würde diese Lösung die Zusammenfassung der Segmente in jeweils einer eigenen Gruppe bedeuten und den Zugriff auf die Inhalte stark vereinfachen. (Diese Änderung wäre durch die dann eingeführten Substrukturen inkompatibel mit den bisherigen Implementierungen.)
3.9. v2.x: explizite Nachrichtenstrukturen/BNF
Ein äquivalentes Problem zu den Segmentstrukturen ist die Wiederverwendbarkeit kompletter Nachrichten. Beispielsweise setzen sich die ca. 60 ADT-Nachrichten aus drei Basisstrukturen zusammen, wenn man die wenigen Query-Nachrichten unberücksichtigt läßt:
- ADT-Basisnachricht
- Merge-Nachricht
- Link-Nachricht
Die Basisnachricht variiert für die meisten ADT-Nachrichten geringfügig im Umfang (optionale Strukturen werden weggelassen) oder in der Reihenfolge der Segmente (welche nicht immer hundertprozentig gleich ist). Dies offenbart einen Nachteil in der nicht durch ein Metamodell unterstützen Vorgehensweise bei der Definition des Standards: Im Prinzip gleichartige Nachrichten variieren und müssen dediziert entwickelt werden. Neben dem zusätzlichen Entwicklungsaufwand für die Hersteller wird der Abstimmungs- und Pflegeaufwand für den Standard selbst unnötig erhöht.
Abhilfe schafft hier in einem ersten Schritt die Einführung eines "Message Structure Identifiers", der exakt gleiche Nachrichten als solche kenntlich macht. Dieser ist mit der Version 2.3.1 eingeführt worden.
Anm.: Leider kommt es trotzdem immer wieder vor, dass bei der Weiterentwicklung des Standards dieser Identifikator nicht berücksichtigt wird, so dass Nachrichten mit vormals gleicher Struktur eine neue Struktur aufweisen.
In einem zweiten Schritt sollte diese MsgStructID dazu benutzt werden, doppelte Nachrichtenspezifikationen im Standard zu eliminieren und damit dem Umfang des Standards zu reduzieren, da jede Struktur dann nur noch einmal aufgeführt wird.
Anm.: Dieser Vorschlag führt zur zu einem Kompatibilitätsbruch, würde dafür das Problem varierender
Strukturen endgültig lösen, da es dann jede Struktur nur noch einmal gibt.
Dieser Vorschlag wird von der Community wegen der Kompatibilitätsprobleme nicht akzeptiert! Umgekehrt werden aber die
durch diese "Inkonsistenzen" ausgelösten Diskussionen und die damit verbundenen Zusatzaufwendungen nicht thematisiert.
Nach Meinung des Autors summieren die sich daraus ergebenden Aufwendungen zu einer Größenordnung, die einen
derartig drastischen Schritt rechtfertigen.
3.10. v2.x: Nationale Weiterentwicklung
Nationale Besonderheiten (bspw. die Versichertenkarte in Deutschland, die Informationen für die DRG-Abrechnung,
die Nutzung von ICD-10 (die Amerikaner setzen immer noch auf ICD-9 und verkennen die damit nicht auftretenden
Probleme, der erweiterte Zeichensatz in Rußland und Japan, die speziellen Namensgebungen in den unterschiedlichen
Ländern, etc.) führen zwangsweise zu Erweiterungen. Der HL7-Standard hat dafür die sog. Z-Segmente und die Z-Events
vorgesehen.
Diese sollten eingesetzt werden, um auftretende Probleme schnell und ggf. individuell lösen zu können.
Der Einsatz eines Z-Segmentes kann zwei verschiedene Ursachen haben:
- Der Standard sieht dafür bereits eine Lösung vor, die allerdings nicht bekannt ist bzw. - bewußt oder unbewußt - nicht umgesetzt wird.
- Der Standard sieht dafür tatsächliche keine Lösung vor.
Im ersten Fall sollte die bereits vorhandene Lösung korrekt umgesetzt werden. (Es gibt aber auch Beispiele, die bewußt diesen Weg nicht beschreiten: die Nachrichtenprofile for HL7 v2.4 des NHS in UK oder die Telefonnummern des Patienten am Bett in Österreich.)
Im zweiten Fall sollten die Ergänzungen in den jeweiligen Z-Segmenten als Erweiterungsvorschlag in den Standard eingebracht werden. Nach Meinung des Autors ist jegliche derartige Lösung Grund genug, um einen Erweiterungsvorschlag einzubringen, denn wenn ein Hersteller eine derartige Erweiterung braucht, dann wird es sicherlich auch einen zweiten geben!?
3.11. V3: Nationale Weiterentwicklung
In der Version 3 stellt sich diese Situation zwar anders dar, ist aber im Prinzip ähnlich. Siehe hierzu auch die Abschnitte über CMETs (substitution) sowie Localisation Rules.
3.12. v2.x: XML Encoding
Das XML-Encoding für die Version 2.x ("HL7.xml") basiert im Prinzip auf der Nutzung von XML-Strukturen und Elementen, die sich an dem Standard-Encoding (ER7) orientieren. Damit werden die Strukturen kompatibel zu ER7 umgesetzt. Allerdings gibt es einige Unterschiede:
- Segmentgruppen werden eindeutig ausgezeichnet. Damit rücken die Strukturelemente eine Ebene tiefer und sind direkt adressierbar.
- Felder werden über den Datentyp ausgedrückt, insofern es sich um einen zusammengesetzten Datentypen handelt. Dies wird dann problematisch, wenn in der Weiterentwicklung der Datentyp durch zusätzliche Komponenten weiter verfeinert wird, was dann zu Inkompatibilitäten führt. Das gleiche Resultat kommt zustande, wenn spezielle Implementierungen zusätzliche Komponenten einführen.
Zum Einen haben die darauf basierenden Implementierungen einen gewissen Vorteil (von den XML-Tools abgesehen), sofern die Strukturen eindeutig identifizierbar sind. Zum anderen führen Weiterentwicklungen zu Inkompatibilitäten.
3.13. v2.x: Nachrichtenprofile
In Deutschland gilt die folgende Hierachie: Auf Basis des Originalstandards wurde über die
vergangenen 15 Jahre eine Übersetzung/Interpretation angefertigt. Diese informative - aber inoffizielle
- Fassung ist die Grundlage für die Nachrichtenprofile, die auch über die HL7-Benutzergruppe
abgestimmt wurde und somit als normativ gelten.
Auf dieser Basis kann dann jeder Hersteller weitere Einschränkungen festlegen und umsetzen:
Abbildung 7: Profil-Hierarchie
Auf dieser Grundlage wurden bspw. für die Aufnahme drei verschiedene Profile definiert. Welche davon dann realisiert wird, sollte dann im Nachrichtenkopf angegeben werden:
- Standard-Aufnahme
- Aufnahme für DRG
- Aufnahme zu Abrechnungszwecken mit Versichertendaten
Ein wichtiger Punkt ist letztendlich die Dokumentation: Jede Realisierung der Grundlagenspezifikation stellt ein eigenes Profil dar. Nur wird es relativ häufig nicht als solches gesehen und daher auch nicht dokumentiert.
Eine weitere Frage ist die der HL7-Konformität, d.h. ist ein solches Profil nach den allgemeinen Vorgaben definiert.
Aus der obigen Abdildung kann entnommen werdne, dass mehrere Profile jeweils aufeinander aufbauend definiert werden. Normalerweise werden diese dann über die entsprechenden OIDs eindeutig identifiziert. Allerdings sind diese OIDs nur bedingt in einem Register hinterlegt, so dass diese nur schwer oder gar nicht prüfbar sind.
3.14. v2.x: Kompatibilität zwischen den Versionen
Die 2er-Versionen sind bezogen auf die Standard-Encoding-Rules vom Konzept her aufwärtskompatibel. Eingeschränkt wird dies nur in 2 Punkten. Zum einen durch semantische Änderungen an den Feldinhalten. So kann es vorkommen, dass Information in anderen Feldern untergebracht werden. Zum anderen in Bezug auf die Kodierung unter Verwendung der XML-Syntax. Hierbei werden die Datentypen der Datenelemente als Tagnamen herangezogen, sofern sie mehr als eine Komponente umfassen. Sollten also atomare Feldinhalte in Komponenten aufgeteilt werden, so wird bei der Kodierung eine zusätzliche Ebene eingezogen. Derselbe Effekt tritt auf, wenn Segmente bei der Erweiterung von Nachrichten dann neuen Gruppen zugeordnet werden.
Das erste Problem lässt sich dadurch lösen, dass Datentypen nicht über einen eigenen Elementnamen umgesetzt werden, sondern in Bezug auf die Komponentendarstellung übermittelt werden:
| Beispiel 1 alt | neu | Erklärung | Beispiel 2 alt | neu | Erklärung |
|
|---|---|---|---|---|---|---|
| ... | ... | ... | ... | |||
| <PID-5> | <PID-5> | <PID-6> | <PID-6> | |||
| <XPN.1> | <PID-5.1.1> | 1. Subkomponente der 1. Komponente | <IS.1> | 1. Komponente des Feldes | ||
| Meier | Meier | M | M | |||
| </XPN.1> | </PID-5.1.1> | </IS.1> | ||||
| </PID-5> | </PID-5> | </PID-6> | </PID-6> | |||
| ... | ... | ... | ... |
Tabelle 4: Vorschlag XML-Encoding
Damit erhöht sich der Aufwand für die Definition der Schemata zwar erheblich, löst es doch zugleich ein weiteres nicht benanntes Problem: Mitunter erhalten bestimmte Datentypen zusätzliche Einschränkungen, wenn sie bei einem bestimmten Feld genutzt werden. Beispiel: "CE", "CNE" und "CWE".
Das zweite Kompatibilitätsproblem lässt sich nur lösen, wenn die bereits beschriebenen impliziten Informationsinhalte explizit gemacht werden. Für dieses Problem bedeutet es, dass alle Segmente daraufhin überprüft werden, ob für sie später eine Gruppierung mit weiteren Segmenten in Betracht kommt. Das lässt sich aber nur sehr eingeschränkt umsetzen, da Segmente aus zukünftigen Versionen noch nicht absehbar sind. Von daher ist dieses Ziel nicht zu erreichen.
3.15. Zeichensatz
Ein Problem ganz anderer Art und das auch nur unter bestimmten Bedingungen auftritt ist das des genutzten Zeichensatzes. Die einzelnen Implementierungen schreiben relativ unbedarft die Informationen aus dem Datensatz direkt in die Nachrichteninstanz. Dabei wird meistens weder:
- der Zeichensatz angegeben,
- ein Encoding (hier: Escaping) durchgeführt, bzw.
- noch ein Wechsel des Zeichensatzes angegeben.
Es wird erwartet, dass die Gegenseite schon denselben Zeichensatz nutzt bzw. die übermittelten Daten direkt verwerten kann. So sind die damit verbundenen Probleme auch noch nicht aufgefallen:
Ein Punkt dabei sind die Escape-Sequenzen: Zum Umschalten zwischen den diversen Zeichensätzen sind Escape-Sequenzen notwendig. Diese sind aber nicht für alle Zeichensätze definiert worden. Im Prinzip muss für jeden lt. Tabelle 0211 erlaubten Zeichensatz eine entsprechende Escape-Sequenz vorhanden sein, was aber nicht der Fall ist.
Die Japaner nutzen für ihren präferierten Zeichensatz (ISO IR87) die intern definierten Escape-Sequenzen. Die bisherigen Implementierungen zeigen, dass dies wohl funktioniert.
InM WG hat am 16.3.10 beschlossen, die Zeichensätze UTF-16 und UTF-32 nicht mehr zuzulassen. Diese
beiden sind im Prinzip nur alternative Darstellungsformen von UNICODE und können damit durchaus
auch durch UTF-8 repräsentiert werden. Damit wird eine grundsätzliche Inkompatibilität zwischen
den verschiedenen Anwendungen ausgeschlossen.
UTF-8 hingegen ist so konzipiert, dass grundsätzliche keine Probleme durch Überschneidungen mit
ASCII auftreten. Allerdings muss dann für die Festlegung der Delimiter beachtet werden, dass
diese mit 7-Bit dargestellt werden können.
3.16. V3: Lokalisation
Die Lokalisation von V3 Elementen geschieht neben den Austausch der CMETs (s.u.) über Demotion bzw. Promotion der Datentypen. Damit ist gemeint, dass die jeweilig eingesetzten Datentypen durch einfachere bzw. generischere ersetzt werden. Genaueres regelt hierzu das Dokument "Refinement, Localisation and Constraints" des HL7 V3 Standards.
Mit Demotion ist im Prinzip die Vereinfachung eines spezifizierten Datentyps gemeint. So wird bspw. "IVL<TS,TS>" (ein Zeitintervall) zu "TS" (ein Zeitpunkt) reduziert. Promotion ist dann der genau umgekehrte Vorgang.
3.17.CMET-Substitution
Die Lokalisierung von Nachrichten und Modellen allgemein auf nationaler Ebene geschieht über den Austausch der sog. CMETs, d.h. in den jeweiligen Modellen werden die entsprechenden CMETs übergreifend ausgetauscht. So könnte bspw. das CMET "Patient" in Deutschland so modifiziert werden, dass immer Informationen über die KV-Karte bzw. eGK enthalten sind.
3.18. V3: Interversion-Compatibility
Das HL7 Development Framework (HDF) legt fest, dass im Prinzip ein algorithmischer Vorgang
für die Umsetzung der Domänen-Modelle von der abstrakten Darstellung unter Nutzung des RIM
bis hin zur Sequenzialisierung als XML-Struktur verantwortlich ist. Damit sollte aus den gleichen
Eingabeparametern dasselbe Ergebnis erzielt werden können.
Prinzipiell ist eine derartige Aussage korrekt, allerdings variiert mit der Weiterentwicklung
des RIM ein ganz wichtiger Parameter, so dass hier verschiedene Strukturen erzeugt werden,
die zueinander inkompatibel sind. (Das ist mitunter ein Punkt, der diese Arbeit begründet.)
Ausschlaggebend sind die möglichen Verschiebungen von Attributen.
Wichtig dabei ist die sogenannte ITS - die Implementable Technology Specification, die die
Umsetzung der Modelle - hier: nach XML - regelt. Die bisherige ITS nutzt für die Umsetzung
dabei die Namen der Klassen (vgl. Vortrag auf der IHIC 2009 sowie GMDS 2009).
Das 2010 vorgebrachte Proposal soll nun die RIM-Klassennamen verwenden, um die Variabilität
und damit die Inkompatibilitäten in der Weiterentwicklung sowohl des RIMs als auch der
Domänenmodelle einzugrenzen.
Ein grundsätzliches Problem mit der bisherigen ITS ist, dass die Attribute classCode und moodCode
prinzipiell über die Semantik und damit die Validierung der Instanzen bestimmen. Umgekehrt sind
diese Informationen in der XML-ITS ebenfalls als Attribute realisiert, so dass eine Validierung
grundsätzlich nicht über die XML-Schemas erfolgen kann:
Umgekehrt würde jeder XML-Entwickler ein Schema genau für diesen Zweck einsetzen und versteht
deshalb nicht, warum das nicht geht.
Die neu zu entwickelnde ITS hat dies zu berücksichtigen.
3.19. V3: Mixtur aus Versionen
Wie bereits ausgeführt wird die Version 3 auf Grundlage des RIMs entwickelt. Wie in der Arbeit
ausgeführt ist das aber nicht allein relevant. Hinzu kommen die Datentypen sowie die Vokabularien,
so dass in einer Implementierung eine Kombination aus zumindest diesen drei Aspekten relevant ist.
Zum Glück hat sich an den Datentypen in den ersten Normative Editions (2005-9) nichts geändert,
so dass alle auf dem Rel.1 der Datentypen aufbauen. Genauso hat sich die XML-ITS nicht geändert,
so dass ausschließlich das RIM und die Vokabularien berücksichtigt werden müssen.
Ab 2010 wird sich das ändern, da dann sowohl die Datentypen in Rel.1.1 und Rel.2 verfügbar sein werden,
als auch alternative ITSes zur Verfügung stehen. Damit dürften sich die Aufwendungen für die
diversen Implementierungen erhöhen, wenn nicht von Anfang an bei der Umsetzung auf einen generischen
Ansatz geachtet wurde.
Es ist zwar einfacher, die XML-Validierung von Nachrichten einzusetzen, da das zum Standard-Repertoir
eines jeden XML-Entwicklers gehört, dies aber wie bereits ausgeführt nicht zum HDF-Ansatz passt.
3.20. CDA - Clinical Document Architecture
Die "Clinical Document Architecture" wurde ursprünglich entwickelt, um beliebige medizinische/klinische Dokumente austauschen zu können. Aufgrund des Migrationsszenarios steht dann neben den Metadaten der eigentliche Text im Vordergrund. Jedes CDA-Dokument MUSS zur Erhaltung der Lesbarkeit Text enthalten, wobei es keine Rolle spielt, ob dieser Text manuell erstellt oder durch ein Programm generiert wurde.
3.20.1 Levels
Ein wichtige Rolle - und auch einer der größten Vorteile von CDA - sind die unterschiedlichen Level:
| Level | Beschreibung |
|---|---|
| 1 | nur Text: das Dokument enthält nur Text bzw. keinerlei eindeutig identifizierbaren Inhalt |
| 2 | Codes informieren über die Inhalte der einzelnen Abschnitte |
| 3 | damit werden die Daten in einer strukturierten Form kommuniziert |
Neuere Vorschläge versuchen hier noch eine weitere Unterteilung zu realisieren. So könnte es ein
Level 0 geben, wo nur embedded Objects vorhanden sind, d.h. Binärdaten, die nicht ohne weiteres
auswertbar sind. (IHE ITI XDS-SD wäre eine solche Spezifikation.)
Umgekehrt soll es noch ein Level 4 geben, das über interne Referenzen (Verlinkung der Sektionen
untereinander) Auskunft gibt.
3.20.2 Releases
Das erste Release von CDA wurde 1999 veröffentlicht. Damals wurde die Idee angekündigt,
zusätzliche Levels definieren zu können, um strukturierte Daten austauschen zu können.
Allerdings kam es nie dazu. In Deutschland wurde damals SCIPHOX gegründet, um den XML-Ansatz
aufzugreifen, um eine sektorenübergreifende Kommunikation auf Basis von XML zu etablieren.
Die damals in Deutschland spezifizierten Small Semantic Units (SSUs) entsprachen in etwa dem
heute bekannten und genutzten Level 3.
Das zweite Release, 2005 veröffentlicht, basiert nun vollständig auf der Version 3.
Ebenso wurden die Datentypen übernommen.
Dieses Release enthält auch im sog. Body eine Sammlung von Aktivitäten ("Acts"), die heute
in einer allgemeineren Form separat als Clinical Statement Pattern von sich Reden gemacht
hat.
Die gesamte Spezifikation zusammen mit den Datentypen Rel.1 bildet eine derart generische Vorgabe,
so dass sie so von keiner Anwendung umgesetzt werden kann. Deshalb müssen hierzu Leitfäden
geschrieben werden, die eine Implementierung regeln:
Dazu gehört neben dem in Deutschland bekannten VHitG-Arztbrief auch die bei IHE veröffentlichen
Content Module im Bereich Patient Care Coordination (PCC).
Das dritte Release befindet sich derzeit in Vorbereitung. In diese Weiterentwicklung fließen all die bisher nicht umgesetzten Anforderungen als auch zusätzliche Ideen ein. Dazu kommt noch die Unterstützung der HL7 V3 Datentypen in Release 2.
Derzeit wird ebenfalls überlegt, ob man ein alternatives XML-Schema ("Green CDA") definieren kann, das eine Umsetzung für Hersteller erleichtert.
3.20.3 SDA - Structured Document Architecture
Eine Weiterentwicklung ganz anderer Art ist die Realisierung der Structured Document Architecture, mit der die Abstraktion erhöht wird. Damit ist CDA dann "nur noch" eine Spezialfassung von SDA. Eine andere Spezialisierung wäre dann bspw. SPL, das Structured Product Labeling.
3.21. Konformanztests
Zur Verbesserung der Interoperabilität gibt es drei Möglichkeiten von Tests:
- mehrere Systeme gegeneinander,
- Nachrichten eines Systems gegen eine öffentliche Spezifikation und
- ein System gegen seine eigene Spezifikation.
Die erste Variante wird bereits beim IHE Connect-a-thon eingesetzt. Hierbei wird geprüft, ob ein System in einem gegebenen Kommunikationsszenarium die Daten verarbeiten kann, die ein anderes System ihm schickt. (Ein Abgleich der dabei übermittelten Nachrichten wird mangels Zeit eigentlich immer unterlassen.) Letzteres zeigt den pragmatischen Ansatz von IHE. Es kommt darauf an, eine erfolgreiche Kommunikation zwischen den unterschiedlichsten Systemen zu demonstrieren. Dabei sind Nachbesserungen vor Ort zugelassen. Das Ergebnis des Tests wird dann für Messen und Demonstrationen aufgehoben. Dieses pragmatische Vorgehen impliziert aber auch, dass auf diese Weise keine Software entsteht, die durch Kunden offiziell gekauft werden kann. (Es kann nicht unterschieden werden, ob ein Hersteller einen sehr rudimentären Prototypen oder ein fast fertiges Produkt testet. Über den Vergleich der Ergebnisse vergangener Tests kann zwar recherchiert werden, dies ist aber sehr mühsam und garantiert dabei nicht die Produktreife einer getesteten Software.)
Bei der zweiten Variante hat ein Hersteller viele (mehrere tausend) Nachrichten einzureichen, von denen dann eine repräsentative Auswahl (mehrere Hundert) automatisiert überprüft werden. Diese Form wird bspw. von AHML [AHML] favorisiert. Die Prüfung orientiert sich dabei an recht generischen (syntaktischen) Regeln, die mitunter nicht unumstritten sind: So wird bspw. bei einem einfachen Datentyp geprüft, ob es noch eine zweite Komponente gibt.
Da eine Prüfung dieser Art nur gegen constrainable Profiles durchgeführt werden kann, bleiben viele Problemfälle unentdeckt. Dafür ist eine solche Prüfung kostengünstig anzubieten, da auf keinerlei Spezifika eingegangen werden muss.
Die dritte Variante stellt die sog. Zertifizierung von Schnittstellen [ZTG] dar. Hierbei hat ein Hersteller eine Spezifikation einzureichen, die eine gültige Einschränkung eines (einzuschränkenden/Constrainable) Nachrichtenprofils darstellt. Im ersten Zertifizierungsschritt wird dann geprüft, ob diese Spezifikation tatsächlich eine gültige Einschränkung darstellt. In einem zweiten Schritt muss der Hersteller dann beweisen, dass seine Software der eigenen Spezifikation entspricht.
Aufgrund des (derzeit) hohen Grades an manueller Prüfarbeit (Prüfung der Spezifikation, Konfiguration des Systems, Eingabe der Daten aus dem vorgegebenen Testszenario) ist dies eine teure Variante. Allerdings werden auf diese Art die meisten der Problemfälle entdeckt.
Mit diesen drei Varianten wird ein orthogonaler Raum aufgespannt:
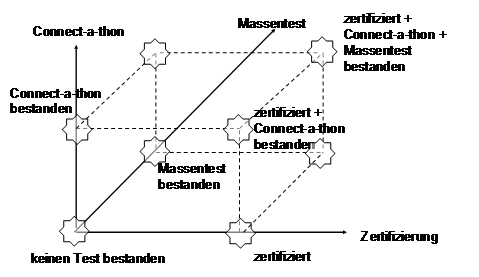
Abbildung 8: die versch. Testverfahren: ein Widerspruch?
Es ist unbestritten, dass ein Test wie beim IHE-Connect-a-thon seinen praktischen Wert hat. Nicht umsonst haben an dem Conect-a-thon 2005 in den Niederlanden über 80 Hersteller mit mehr als 100 Systemen daran teilgenommen - Tendenz steigend. (Allerdings ist hier anzumerken, dass nach mehreren erfolgreichen Teilnahmen die Hersteller nur noch bedingt geneigt sind, die Tests zu wiederholen, so dass für die älteren Profile eine Abnahme zu verzeichnen ist.)
Bei der Zertifizierung stehen die Hersteller jedoch vor einem Dilemma: Die meisten Schnittstellen sind konfigurierbar und können so an unterschiedliche Anforderungen angepasst werden. Um die Vorgaben für die Zertifizierung zu erfüllen und um den Test zu vereinfachen, werden eine Reihe von optionalen Eigenschaften "wegkonfiguriert". Da die Schnittstellenspezifikation allerdings Bestandteil des Zertifizierungsprozesses mit einer Veröffentlichung der Ergebnisse ist, werden dem entsprechend weniger Leistungsmerkmale publiziert.
Ziel muss es sein, auch für HL7 eine Verpflichtung zur Veröffentlichung der Schnittstellenspezifikationen (die sog. Conformance Statements) zu erreichen. Mit dem Zertifizierungsprozess kommt man diesem Ziel indirekt näher.
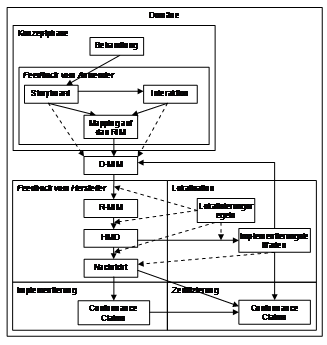
Abbildung 9: Vorgehensmodell
Die Grundlagen für vorangenanntes Vorgehensmodell für HL7 V3 wurde von Kai Heitmann entwickelt und von mir um Conformance Claims für die Implementierung und Zertifizierung ergänzt.
Last Update: March 22, 2010