| Chapters |
| Einführung |
| Schriftsatz |
| Schlußbemerkungen |
| Literaturhinweise |
| Anhang |
3 Typographie
Ausgehend von den gegebenen Randbedingungen soll durch die Anwendung der Regeln der eingegebene und schon nach den Regeln des Schriftsatzes (s. Kap. 2) veränderte Text so aufbereitet werden, daß ein "harmonisches Bild" entsteht. Die daraus resultierenden Fragen betreffen die Definition eines "harmonischen Bildes": Wovon hängt es ab, ob ein Layout gewissen ästhetischen Ansprüchen genügt, und was wird i.allg. unter Ästhetik verstanden?
3.1 Probleme
Jeder Mensch hat intuitiv einen Begriff von Ästhetik. Für die automatische Berechnung eines Layouts müssen aber konkrete Regeln vorliegen, die die unterschiedlichsten typographischen Aspekte betreffen. Das Hauptproblem liegt darin, daß sich diese Regeln gegenseitig beeinflussen und demzufolge ein Ergebnis nicht so einfach berechnet werden kann. Dieses Problem kann durch den Aufbau eines Netzwerkes zur Darstellung der Regelabhängigkeiten, das für eine leichte Berechnung möglichst hierarchisch aufgebaut sein sollte, behoben werden. Des weiteren muß der Schönheitsbegriff für ein Layout durch geeignete Operationalisierung des Wissens, z.B. in Bezug auf Tonwerte und Wirkungen, auf eine Ebene gebracht werden, die einer Berechnung durch einen Computer zugänglich ist.
Nach dieser kurzen Erläuterung kann ein harmonisches Bild verstanden werden als eine Layoutgestaltung, welche typographische Regeln und ihre Implikationen berücksichtigt.
3.1.1 Wissensakquisition
Das oben angesprochene Netzwerk muß durch eine entsprechende Regelmenge mit Wissen gefüllt werden. Da zu dieser Thematik nur wenig Literatur zur Verfügung steht, muß die Wissensakquisition vor Ort, d.h. in einer Druckerei, durchgeführt werden, wenn dort Schriftsetzer und Drucker bereit sind, sich über diese Thematik zu "unterhalten" und Teile ihres Wissens preiszugeben. Durch diese Gespräche ergeben sich eine ausreichende Menge an Implikationen, z.T. sogar schon konkrete Werte für einzelne Regeln.
Aus den Aufzeichnungen lassen sich verschiedene Kategorien von Regelmengen extrahieren, von denen ein Teil direkt in das System eingegeben werden kann und der andere Teil noch weiter unterteilt werden muß.
3.1.2 Natürlichsprachliche Begriffe
Ein weiterer Punkt soll die Beeinflussung des Layouts durch natürlichsprachliche Begriffe sein. Darunter ist z.B. die Wahl einer schwereren bzw. dunkleren Schriftart unter der Bedingung zu verstehen, daß eine bedrückende Wirkung erzielt werden soll. Für einen Benutzer ist es wesentlich einfacher, seine Anforderungen in der Umgangssprache zu formulieren, als so lange verschiedene Parameter - von denen ein Desktop-Publishing-System sehr viele zur Verfügung stellt - einzustellen, bis ein Layout erzeugt wird, das seinen Ansprüchen genügt. Ein wissensbasiertes System sollte in der Lage sein, aus den natürlichsprachlichen Begriffen so viele Informationen zu extrahieren, daß allen benötigten Parametern Werte zugewiesen werden können.
Folgende Fragen müssen dazu geklärt werden:
* Wie können einzelne Parameterausprägungen zu natürlichsprachlichen Begriffen zusammengefaßt werden?
Oder andersherum gefragt:
* Welche Möglichkeiten bestehen, einem Zweck bzw. einer Wirkung eine Schriftart mit entsprechenden Eigenschaften zuzuordnen?
* Welche verschiedenen Zwecke und Wirkungen können definiert werden?
3.1.3 Anforderungen der Typographen
Damit ein Typograph weiß, was er mit einem Text machen soll, wenn er ihn bekommt, bezieht sich seine erste Frage auf den Zweck, der mit diesem Text verfolgt werden soll. Damit muß die Menge der Texte nach verschiedenen Zwecken klassifiziert werden, d.h. es muß eine Einteilung in geeignete Dokumentenklassen vorgenommen werden.
3.2 Grundlagen von Expertensystemen
"Die Herkunft des Wortes gibt einen Hinweis: als Experte wird in der allgemeinen Umgangssprache jemand bezeichnet, der die Fakten und Regeln ... aus einem bestimmten Wissensgebiet besser beherrscht und besser zu manipulieren versteht als die Mehrzahl aller anderen Menschen.
Ein Expertensystem ist dementsprechend ein Computersystem, welches gebietsspezifisches Expertenwissen speichern, verwalten, gezielt auswerten und zu Auskünften an einen Benutzer *
oder zur Abwicklung bestimmter Aufgaben ... nutzen kann. Deshalb redet man häufig - und vielleicht besser - statt von 'Expertensystemen' auch von wissensbasierter Software." (/Schnupp 87/, S. 1)
Um konventionelle Software von der wissensbasierten zu unterscheiden, benötigt man nach /Schnupp 87/ (S. 2) noch einige Zusatzkriterien:
- eine Wissensbasis anstelle einer Datenbasis
- eine Wissensakquisitionskomponente
- eine Inferenzkomponente
- eine Erklärungskomponente
Da nicht jedes Expertensystem alle diese Kriterien erfüllt, sollte es zumindest mehr als ein Kriterium davon besitzen, um als ein solches bezeichnet zu werden.
Eine andere Definition besagt, daß Expertensysteme Computerprogramme sind, die Fähigkeiten von Experten simulieren sollen. Dazu gehören:
- ein Problem verstehen und lösen
- die Lösung erklären
- Wissen erwerben und strukturieren
- seine Kompetenz einschätzen
- Randgebiete überblicken
3.2.1 Schematischer Aufbau von Expertensystemen
Ein Expertensystem besteht aus mehreren Komponenten, deren Zusammenwirken sich wie folgt darstellen läßt:
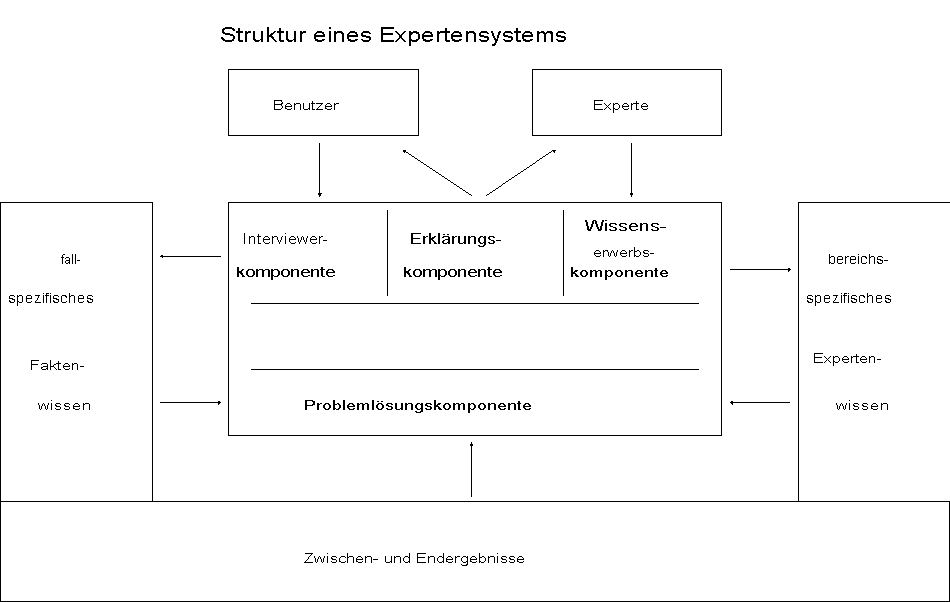
Abb. 3.1: Struktur eines Expertensystems /Puppe 86/
Die beiden Hauptbestandteile sind die anwendungsspezifische Wissensbasis (außen) und das bereichsunabhängige Steuersystem (Shell, innen). (/Puppe 86/, S. 2)
Die Wissensbasis enthält drei Typen von Wissen:
- bereichsspezifisches Expertenwissen, das sich während einer Konsultation nicht ändert;
- fallspezifisches Faktenwissen, das der Benutzer während einer Konsultation eingibt;
- Zwischen- und Endergebnisse, die das System während einer Konsultation herleitet.
Das Steuersystem besteht aus folgenden Komponenten:
- Die Wissenserwerbskomponente ermöglicht dem Experten (Knowledge Engineer), sein Wissen dem Expertensystem einzugeben und später zu ändern.
- Die Interviewerkomponente (Dialogkomponente) führt den Dialog mit dem Benutzer, und/oder sie liest automatisch erhobene Meßdaten ein.
- Die Problemlösungskomponente wendet das Expertenwissen auf die vom Benutzer eingegebenen Fakten an, um eine Lösung seines Problems zu finden. Häufig müssen dazu weitere Daten angefordert (erfragt) werden.
- Die Erklärungskomponente macht die Vorgehensweise des Expertensystems für den Benutzer nachvollziehbar, z.B. zur Plausibilitätskontrolle und Fehleranalyse.
Um überhaupt mit Expertensystemen arbeiten zu können, muß erst einmal das Wissen, das den jeweiligen Experten direkt oder auch nur indirekt zur Verfügung steht, in einem solchen System abgebildet (gespeichert) und eine Methode entwickelt werden, wie das Wissen auf die jeweiligen Daten anzuwenden ist.
3.2.2 Wissensrepräsentationsarten
Im Laufe der letzten Jahre sind mehrere Formalismen zur Wissensrepräsentation entwickelt worden, von denen zwei besonders herausragen:
- Produktionsregeln und
- Frames
Produktionsregeln folgen mehr dem humanen Denken, weil sie in einem "Wenn-dann"-Muster niedergeschrieben werden können. Das gesamte Expertensystem besteht dabei aus drei Teilen:
- der Datenbasis
- der Regelmenge
- dem Interpreter (Inferenzmechanismus)
Der Interpreter (Inferenzmechanismus) untersucht die Bedingungen der einzelnen Regeln und führt die entsprechende Aktion auf der Datenbasis aus, sobald eine Bedingung als wahr erkannt wird.
<Bedingung> --> <Aktion>
Der Interpreter hat nur die Aufgabe, die Regelmenge daraufhin zu durchsuchen, ob eine Bedingung (Konjunktion von Einzelbedingungen) zutrifft, so daß die zugehörige Aktion (Menge von Einzelaktionen) ausgeführt werden kann. Die Reihenfolge, in der der Interpreter die Regelmenge durchsucht und passende Regeln anwendet, ist abhängig davon, welche Kontrollstrategie und welcher Suchalgorithmus (s. auch Kap. 3.2.3) Anwendung findet. Gegebenenfalls wird den einzelnen Aktionen ein Sicherheitsfaktor ("Certainty Factor") zugewiesen, der die Sicherheit des Zutreffens der Bedingung widerspiegelt. (/Shortliffe 81/)
Im Gegensatz zu den Produktionsregeln stehen die Frames, mit denen in eher deklarativer Weise stereotype Situationen und Objekte beschrieben werden. Dabei wird die Tatsache ausgenutzt, daß sich relativ viele Werte auf ein und dasselbe Objekt beziehen.
Ein Prototyp-Frame ist eine Hierarchie von zusammengesetzten Datenstrukturen zur Darstellung von prototypischem Wissen.
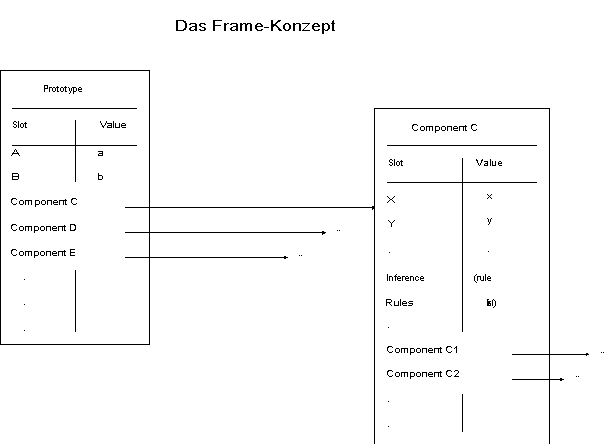
Abb. 3.2: Das Frame-Konzept /Aikins 83/
Die einzelnen Prototypen enthalten verschiedene Typen von Slots:
- General Slots
- Control Slots
- Rule Slots
- Components
Der General Slot dient internen Verwaltungsaufgaben (z.B. durch Zeiger auf andere Prototypen), Erklärungen und der Kommunikation mit dem Benutzer. Der Control Slot beaufsichtigt die Anwendung verschiedener Regeln z.B. bei der Instantiierung oder Deaktivierung bzw. Bestätigung oder Widerlegung der jeweiligen Prototypen. Der Rules Slot enthält eine Liste aller für diese Komponente verwendbaren Regeln (z.B. Regeln zur Suche nach nicht benutzten oder nicht ausreichend erklärten Fakten, nach weiter einschränkenden Tests oder einfach zur Zusammenfassung vorhandener Informationen). Die Components können für diesen Prototypen verschiedene Informationen bereitstellen, z.B. mögliche (erlaubte) Werte, Standardwerte (default values), fehlerhafte Werte, Inferenzregeln zur Herleitung nicht vorhandener Werte, Prozeduren, die bei Bekanntwerden eines Wertes ausgeführt werden (attached procedures), und Gewichtungsfaktoren für die Bedeutung dieser Komponente. Durch spezielle Sloteinträge ("Typ" und "Instanzen") können Vererbungshierarchien aufgebaut werden, wobei die Unterframes die Eigenschaften ihrer Vorgänger übernehmen oder überschreiben können.
Mit diesen Mechanismen ermöglichen Frames strukturierten Wissenserwerb (Ausfüllen der Slots mit Werten), effiziente Abspeicherung in Hierarchien und Formulierung von Erwartungswerten als Defaults.
Neben diesen beiden Repräsentationsarten, die in den meisten Systemen Anwendung finden, gibt es noch andere Konzepte:
Ein semantisches Netzwerk (von Quillian 1968 entwickelt) soll das assoziative Denken des Menschen simulieren. (/Schefe 86/, S. 12) Das Netzwerk ist ein bewerteter, gerichteter Graph, dessen Knoten eine semantische Einheit und dessen Kanten eine semantische binäre Relation darstellen. Wichtige Fakten über ein Objekt können durch die Knoten hergeleitet werden, mit denen dieses Objekt verbunden ist. Der Vorteil dieser Darstellungsart ist das einmalige Vorkommen eines Objektes innerhalb dieses Netzes, so daß jegliche Information bzgl. dieses Objektes über diesen Knoten erfragt werden kann.
Die PROLOG-Regeln
sterblich(X) :- lebewesen(X).
und
lebewesen(sokrates).
lassen sich folgendermaßen darstellen (gestrichelte Linien):
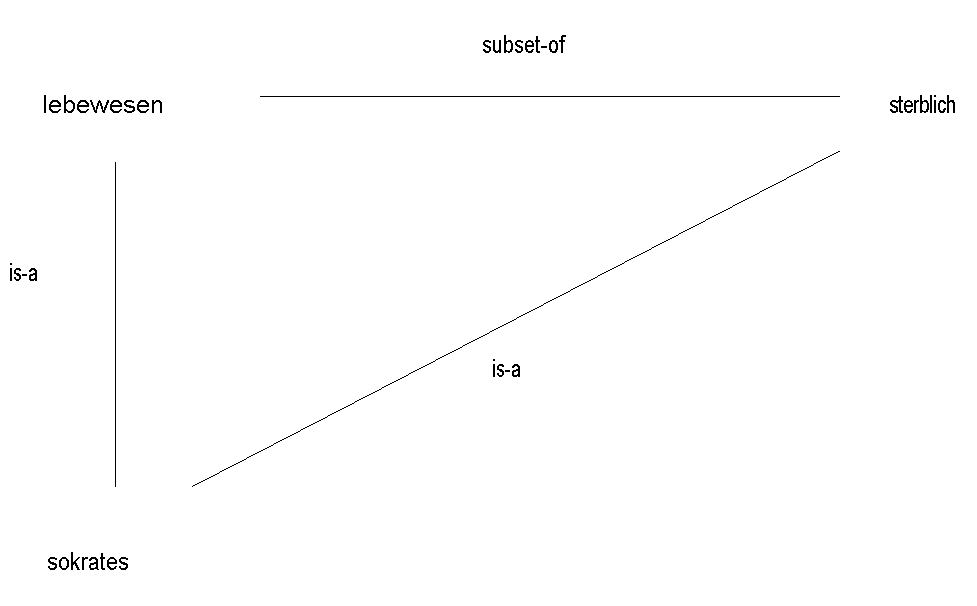
Abb. 3.3: semantisches Netzwerk (Beispiel 1)
Durch den Inferenzprozeß läßt sich daher ableiten (oben durch die gepunktete Linie verdeutlicht):
sterblich(sokrates).
Die semantische Interpretation hängt dabei allein von dem Algorithmus ab, der dieses Netzwerk verwaltet. Deshalb ist ein Schluß, der durch den Inferenzalgorithmus gezogen wird, nicht automatisch in einem logischen Sinne gültig:

Abb. 3.4: semantisches Netzwerk (Beispiel 2)
Dieser Ausschnitt aus einem Netz könnte so interpretiert werden, daß Rotkehlchen (Pinguine) Flügel haben, da Rotkehlchen (Pinguine) Vögel sind und Vögel Flügel haben.
Einem Knoten können zusätzlich folgende Angaben zugeordnet werden:
- fallspezifisches Wissen
- wie weit ist der Knoten gesichert
- Zeitangabe darüber, wann die Angabe erst-/letztmalig auf den Knoten zutraf
- Typangabe
- spezifische Angaben (z.B. Meßwerte)
Inferenznetze sind bewertete, gerichtete Graphen ohne Schleifen, deren Knoten Aussagen oder Hypothesen mit positiven/negativen oder unbekannten Evidenzwerten und dessen Kanten Implikationsrelationen darstellen.
Die Ableitung von neuem Wissen geschieht dann z.B. durch die Fortpflanzung von Wissen von einem Knoten auf einen anderen mittels Entscheidungstabellen (Regelmengen). Diese Tabellen geben an, wie und unter welchen Bedingungen das in den Ausgangsknoten gespeicherte Fallwissen auf den Zielknoten übertragen werden kann. Das Einfügen bzw. Ändern von Wissen, das einem Knoten zugeordnet ist, wird als Ereignis angesehen, welches sich auf andere Knoten fortpflanzt und hier durch Änderung bzw. Schaffung neuer Wissenseinträge zu neuen Ereignissen führt. Dieser Vorgang zieht sich dann durch das gesamte Netzwerk. Die Semantik wird durch die für das Netz definierten Such-, Traversierungs- und Inferenzalgorithmen spezifiziert.
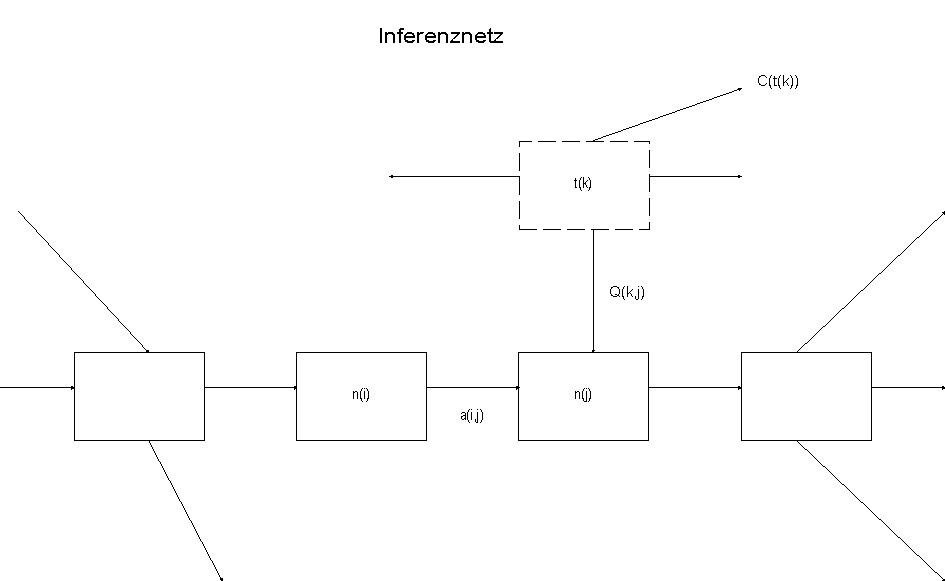
Abb. 3.5: Inferenznetz
| n(i), n(j): | Zustand (Wege durchs Netz) |
| a(i,j): | wie häufig n(j) durch n(i) hervorgerufen wird; Werte aus {0..1} |
| t(k): | Test/Beobachtung |
| Q(k,j): | Maß für Zutrauen in n(j) bei beobachtetem t(k); Werte aus {0..1} |
| C(t(k)): | Kosten für Test k |
Als letzter Formalismus soll hier der Actor-Formalismus angeführt werden: Dieser kann als Netzwerk abstrakter Maschinen aufgefaßt werden, die ein sequentielles Programm unter einem lokalen Zustand abarbeiten. Das Ergebnis wird dann als Zustandsänderung und als eine Nachricht an den aufrufenden Actor registriert.
3.2.3 Inferenzmethoden
Die meisten Anwendungsgebiete sind häufig so komplex, daß für eine Generierung des gesamten Lösungsraumes der zur Verfügung stehende Speicherplatz und die Rechenzeit nicht ausreichen. Als Ausweg bleibt nur eine Generierung der jeweils aussichtsreichsten Lösungswege. Dies wird durch eine systematische Anwendung des zur Verfügung stehenden Wissens erreicht. Die verwendeten Inferenzmethoden lassen sich gemäß verschiedener Kriterien kategorisieren:
- Kontrollstrategie
- Suchalgorithmus
- Inferenzproblem
3.2.3.1 Kontrollstrategien
Die Kontrollstrategie dient zur Entscheidung, in welcher Weise die Operationen auf der Datenbasis ausgeführt werden. Nachfolgend ist eine Tabelle dargestellt, die einige der wichtigsten Architekturen von Problemlösungskomponenten enthält. Bei der Auswahl der für das Problem geeignetesten Strategie spielt die Problemklasse, die Komplexität des Anwendungsgebietes und die entsprechende Repräsentation des vorhandenen Wissens eine Rolle:
| Strategie: | Komplexitätsreduktion und Beschreibung |
|---|---|
| Forward-Chaining (data driven, event driven, bottom-up): | Herleitung aller Schlußfolgerungen aus den gegebenen Daten (Veränderung des aktuellen Zustandes in Richtung auf einen geg. Zielzustand). |
| Backward-Chaining (goal driven, expectation driven, top-down): | Suche nach allen Regeln (Beweisen), die das Ziel unterstützen, und Überprüfung der dazu benötigten Vorbedingungen (rekursive Vereinfachung des Zielzustandes in unmittelbare Vorbedingungen, bis eine Lösung direkt abgeleitet werden kann). |
| Phasenteilung: | Zerlegung in Teilaufgaben, die unabhängig voneinander verarbeitet werden können (Prinzip "Teile und herrsche"). |
| Establish-Refine: | Schreitet von allgemeinen Hypothesenkategorien entlang einer Hierarchie zu immer spezielleren Hypothesen voran (Abarbeiten eines hierarchischen Lösungsbaumes). |
| Generate-and-Test: | Frühes Erkennen schlechter Lösungszweige (early pruning), wobei im Gegensatz zu Establish-Refine der Lösungsbaum erst generiert werden muß. |
| Hypothesize-and-Test: | Direktes Aktivieren der interessantesten Hypothesen mit unmittelbar danach erfolgendem Test auf Richtigkeit. |
| Agenda: | Untersuchung mehrerer, gleichzeitig aktivierter Hypothesen nacheinander durch Ablage auf einer Agenda (Stack). |
| Middle-out (island driven): | Ausgehend von einer ziemlich sicheren Hypothese, die sich auf wenige Daten stützt, werden die restlichen Daten entsprechend überprüft. |
| Constraint-Propagation: | Schrittweises Eingrenzen der Lösung. |
| Differential-Diagnostik: | Diese Strategie besteht darin, leicht verwechselbare Diagnosen mit ähnlicher Symptomatik relativ zueinander zu bewerten und die beste Diagnose nur dann zu etablieren, wenn sie erheblich besser bewertet wird als die übrigen Differentialdiagnosen. |
| Scheduler: | Da in einigen Expertensystemen die etablierten Hypothesen nicht weiterverarbeitet werden können, wird ein Plan zum weiteren Vorgehen benötigt; dies ist z.B. bei einigen Spracherkennungssystemen der Fall. |
| Blackboard-Architektur: | Austausch von Daten/Wissen über eine definierte Schnittstelle, um unterschiedliche Wissensquellen verknüpfen zu können (z.B. zum Test bereits erstellter Hypothesen). |
Tab. 3.6: Kontrollstrategien
3.2.3.2 Suchalgorithmen
In einem größeren Expertensystem kommt es häufig vor, daß mehr als eine Regel angewendet werden kann. Dann muß das System eine Regel aus dieser Menge (conflict set) auswählen und anwenden. Die Vorgehensweisen bei der Suche nach einer solchen Regel, die als nächstes angewendet werden kann, sollen nun tabellarisch näher beschrieben werden (search algorithms):
| Suchalgorithmus: | Beschreibung der Vorgehensweise |
|---|---|
| A*-Algorithmus: | Verbesserung der Bestensuche durch eine heuristische Schätzfunktion, die als zu teuer eingeschätzte Lösungspfade einstweilen zurückstellt. |
| Minimax: | Bei der Durchsuchung von Spielbäumen wird auf der Ebene des Minimierers der niedrigste, auf der Ebene des Maximierers der höchste Wert zurückgegeben (die einzelnen Ebenen wechseln sich ab). |
| Alpha-beta: | Verbesserung des Mini-max-Verfahrens durch Propagierung des jeweils besten Wertes einer Ebene als Eckwert für die weitere Suche auf den unteren Ebenen. |
| best-first: | Die Regel, deren Bedingungsteil am besten in den aktuellen Kontext paßt, wird angewendet. |
| breadth-first: | Expansion aller Knoten, die im Lösungsbaum auf derselben Ebene liegen. |
| depth-first: | Expansion des Knotens, der momentan am aussichtsreichsten ist. |
| fixed-ordering: | Die erste Regel, die (ausgehend von einer bestimmten Regelreihenfolge) paßt, wird genommen. |
| heuristic state-space-search: | Der Suchraum wird ggf. mit heuristischen Methoden durchsucht. |
| iterative-deepening: | Ähnlich depth-first wird bis zu einer geringen Tiefe der Lösungsbaum durchsucht. Die dann aussichtsreichsten Lösungsbäume werden iterativ etwas tiefer gehend durchsucht, solange noch entsprechende Resourcen dazu zur Verfügung stehen. |
| length-first: | Der Lösungsraum wird auf einer hohen Abstraktionsebene berechnet, und der Teillösungsraum, der am kürzesten ist, wird dann auf einer etwas niedrigeren Abstraktionsebene verfeinert. |
| means-ends analysis: | (gleichzeitiges Vorgehen durch Forward- und Backward-Chaining)
Der aktuelle Zielzustand wird mit dem aktuellen Zustand verglichen, um eine "Differenz" festzustellen. Diese Differenz wird dann für eine Indizierung der Regeln benutzt, um die Forward-Regel herauszusuchen, die am ehesten die Differenz reduzieren kann. |
| uniform cost (branch and bound): | Zur Auswahl der Regel werden die entstehenden Kosten zu Rate gezogen, die gemäß einer Bewertungsfunktion ausgerechnet bzw. geschätzt werden können. |
Tab. 3.7: Suchalgorithmen
3.2.3.3 Inferenzprobleme
Das Inferenzproblem beschäftigt sich mit der Fragestellung, wie aus bekannten Fakten und Regeln neue Fakten oder Regeln gewonnen werden können, insbesondere mit der Modellierung des intuitiven Begriffes der Inferenz. (/Schefe 86/, S. 102ff)
Arten von Inferenzen:
Beschreibung
Modus ponens (Abtrennungsregel, Deduktion):
A -> B
A
----------
B
Aus der Gültigkeit der Vorbedingung kann auf die Gültigkeit der Nachbedingung geschlossen werden.
Induktion:
A(X), B(X)
A(Y), B(Y)
---------------
Vz: A(z) ->B(z)
Zwei oder mehrere Fakten werden zu einem Gesetz verbunden.
Abduktion (Rückschließen):
A -> B
B
----------
A
Aufgrund der Nachbedingung kann auf das Vorhandensein einer Voraussetzung geschlossen werden.
Default-Reasoning (Vorbesetzung):
Bei einer Regel, die nur vage formuliert worden ist, besteht trotzdem die Möglichkeit, entsprechende Schlüsse zu ziehen, die bei Bekanntwerden von Ausnahmen aber wieder zurückgezogen werden müssen.
Modallogik:
A -> B
A v C
----------
~(==> B)
~(==> ~B)
Hier liegt ein Schluß auf eine Möglichkeit vor. Der obige Schluß besagt, daß weder B noch ~B deduziert werden kann. (/Schefe 86/, S. 106)
Tab. 3.8: Arten von Inferenzen
Ein größeres Problem besteht noch in der Vollständigkeit bzw. Unvollständigkeit der Wissensbasis.
Mit der Closed-World-Assumption wird angenommen, daß alle Fakten, die nicht in der Wissensbasis enthalten sind, nicht gelten. Kann diese Annahme nicht getroffen werden, müssen alle ungültigen Fakten separat repräsentiert werden.
3.2.3.4 Spezielle Mechanismen
In einigen Expertensystemen werden noch zusätzliche Mechanismen benötigt, um das gesamte Wissen handhaben zu können: (/Puppe 86/, S. 6)
| Mechanismus: | Beschreibung |
|---|---|
| Evidenzmodelle: | Unsicherheiten bei der Datenerhebung werden durch Zahlen (Wahrscheinlichkeiten) repräsentiert. |
| Nicht-monotones Argumentieren: | Bei Bekanntwerden einer Ausnahme müssen einzelne Bedingungen wieder zurückgezogen werden können. Dieser Mechanismus ist mit dem Default-Reasoning eng verknüpft. |
| Vorverarbeitung von Daten: | Einzelne Daten müssen aufbereitet werden, bevor sie von einem Expertensystem verarbeitet werden können. |
| Repräsentation der Zeit: | Erkennung von Zeitverläufen durch Berücksichtigung von Zeitpunkten, an denen bestimmte Daten erhoben wurden bzw. Bedingungen zutrafen. |
Tab. 3.9: spezielle Mechanismen
3.2.4 Einsatzgebiete
Die existierenden Expertensysteme können gemäß ihrer Aufgabenstellung in folgende Gruppen unterteilt werden. Es ist durchaus möglich, ein Expertensystem mehreren Kategorien zuzuordnen, da die Übergänge fließend sind: (/Puppe 86/, S. 3 und /Schnupp 87/, S. 22ff)
| Kategorie | zugehöriges Problem |
|---|---|
| Analyse und Diagnose | Wiedererkennen bekannter Muster |
| Reparatur | Erweiterung der Diagnosesysteme um Informationen zur Behebung einer erkannten Störung |
| Überwachung u. Steuerung | Erweiterung der Diagnosesysteme durch Vergleich der Eingabedaten mit Sollgrößen und Ausgabe entspr. Informationen bzw. Ergreifung von Maßnahmen zur Korrektur |
| Konstruktion u. Design | Erzeugung/Suche von Objekten, die bestimmten Anforderungen genügen |
| Planung | Herleitung einer Aktionsfolge, die einen geg. Ausgangszustand in einen best. Zielzustand überführt |
| Simulation | Berechnung der vollständigen Auswirkungen von Ereignissen |
Tab. 3.10: Problemklassen
3.2.5 Evaluierung möglicher Wissensrepräsentationsformen
Als mögliche Wissensrepräsentationsformen bieten sich folgende Konzepte an:
- Das Produktionensystem,
- das Frame-Konzept oder
- das semantische Netzwerk.
3.2.5.1 Das Produktionensystem
Für die Wissensrepräsentation ist am besten ein Produktionensystem geeignet, das aus folgenden Komponenten besteht: (/Nilsson 82/, S. 17)
einem Kontrollsystem (control system)
einer Datenmenge (global database) und
einer Menge von Operatoren (set of production rules).
Das Kontrollsystem benutzt die Menge der Operatoren, um Layoutformen zu erzeugen, die über einen Gesamt-Ästhetik-Wert verglichen werden können. Die Datenmenge für die Typographie besteht aus den Benutzerangaben, z.B. der Zweck des Textes und die gewünschte Wirkung, und den daraus berechneten Angaben. Die Menge von Operatoren ist die Regelmenge, die das Wissen über das Layout und den zugeordneten Ästhetik-Faktor enthält.
Der Vorteil dieser Darstellungsart, die auch in dem vorliegenden System genutzt wird, liegt in der einfacheren Implementierung bzw. Anwendung der einzelnen Regeln und der leichteren Handhabbarkeit (z.B. bzgl. späterer Erweiterungen).
3.2.5.2 Das Frame-Konzept
Bei Verwendung des Frame-Konzeptes zur Wissensrepräsentation müssen die Regeln in einzelne Klassen unterteilt werden können, die eine Hierarchie bilden. Ohne eine derartige Struktur kann der Vorteil, der in dem Frame-Konzept steckt, nicht genutzt werden:
Dieses Frame-Konzept muß verworfen werden, da der Verwaltungsaufwand für die einzelnen Frames und deren Slots zu viel Rechenzeit beansprucht und zu häufig zwischen den einzelnen Frames gewechselt werden muß. Ein weiterer Kritikpunkt ist die Tatsache, daß nicht unbedingt eine Baumstruktur erreicht werden kann, da u.a. bestimmte sprachliche Eigenschaften berücksichtigt werden müssen. Gegen eine derartige Implementierung spricht auch, daß die einzelnen Slots des Layoutgestaltungs-Frames Regeln enthalten, die die endgültigen Werte in einem anderen Slot beeinflussen.
Dazu kommt, daß die Repräsentation des Textes in einem Frame-System sich nicht wesentlich von derjenigen in einem Produktionensystem unterscheiden wird und die Vererbungshierarchie, die implizit in einer derartigen Repräsentation enthalten ist, nicht ausgenutzt werden kann. Das Frame-Konzept bietet demnach als einzigen Vorteil eine (direkt sichtbare) Partition der Regelmenge, die durchaus auch durch eine entsprechende Namensgebung in einem Produktionensystem erzielt werden kann.
3.2.5.3 Das semantische Netzwerk
Das semantische Netzwerk ist als Form der Wissensrepräsentation ebenfalls ungeeignet:
Das Wissen liegt als Regelmenge vor. Die Repräsentation von Regeln in einem semantischen Netzwerk erfordert einen hohen Aufwand, um einen Inferenzprozeß zu entwickeln, der das Wissen, das dann in den einzelnen Knoten und deren Verbindungen untereinander enthalten ist, verwalten und verarbeiten kann. Das Wissen, das in einer einzelnen Regel enthalten ist, müßte als faktisches Wissen in verschiedenen Knoten mit entsprechenden Verbindungen untereinander definiert werden:
"A semantic network attempts to combine in a single mechanism the aubility not only to store factual knowledge but also to model the associative connections exhibited by humans which make certain items of information accessible from certain others." (/Woods 85/, S. 222)
Die Struktur des Textspeichers hingegen (s. Kap. 3.3.9) kann bei einer leichten Änderung der Darstellungsart als ein sehr einfaches semantisches Netzwerk aufgefaßt werden, da es sich bei der Speicherung des Textes um Fakten (Worte und das Wissen über ihre Verwendung) handelt, die über entsprechende Verbindungen (z.B. die Nachfolgerelation über die Wortnummer) miteinander in Beziehung stehen.
3.3 Problemlösung und Bemerkungen zur Implementierung
Für die oben angesprochenen Probleme existieren folgende Lösungsmöglichkeiten:
3.3.1 Festlegung und Definition eines Schriftbildes
Zur Auswahl des endgültigen Schriftbildes bestehen zwei mögliche Vorgehensweisen:
1. Top-down: Jedem einzelnen Zweck wird zuerst eine Menge von möglichen Schriftarten und Layout-Bedingungen (direkte Einschränkung der Parameter für jede einzelne Schriftart innerhalb dieser Menge) zugeordnet. Sobald ein Zweck ausgewählt worden ist, liegt sogleich eine bestimmte Menge von Schriftarten und Layout-Bedingungen fest. Danach können die noch frei wählbaren Eigenschaften aus dieser Schriftartenmenge in Abhängigkeit von den gewünschten Wirkungen (Benutzerangaben), d.h. eine weitere Einschränkung der möglichen Schriftarten und der Ausprägung einzelner Eigenschaften gemäß der vorgegebenen Wirkungen, variiert werden. Dazu ist es notwendig, daß jede einzelne Schriftart gemäß charakteristischen, nicht veränderbaren Eigenschaften klassifiziert wird und die Wirkungseigenschaften einige der möglichen Schriftarten bevorzugen. Die Wirkungseigenschaften benötigen demnach folgende Regeln/ Fakten:
- Ausschlußbedingungen für widersprüchliche Eigenschaften,
- Regeln zur Auswahl des "richtigen Schriftbildes" und
- bei Klartexteingabe Synonyme für gleiche Eigenschaften/Wirkungen.
Ein Vorteil liegt in der leichten Operationalisier- und Erweiterbarkeit der Wirkungseigenschaften, sobald der Charakter einer Schriftart festliegt. Der Nachteil wird aus der sehr großen Daten- und Regelmenge ersichtlich.
2. Bei der Bottom-up-Methode werden Regeln bzw. Fakten festgelegt, nach denen bestimmten Schriftarteigenschaftstupeln (z.B. einer gleichzeitig vorliegenden Neigung und Serifenbildung) bzgl. einer Schriftart ein Charakter zugeordnet werden kann. Damit dieser Charakter eindeutig ist, muß für die Zuordnung eine entsprechend große Eigenschaftsmenge (s. u. a. Kap. 3.3.2) berücksichtigt werden. Nun muß nur noch für eine gewünschte Wirkung die Schriftart, für die entsprechende Schriftarteigenschaftstupel existieren, mit den Schriftarteigenschaften, die am besten passen, herausgesucht werden. Sollten bei mehreren gewünschten Charakteren mehrere Schriftarten ausgewählt werden, müßte über eine entsprechende übergeordnete Regel diese Schriftartenmenge auf eine einzelne Schriftart abgebildet oder über entsprechende Gewichtungsfaktoren eine Schriftart bevorzugt werden.
Ein Vorteil liegt in der relativ kleinen Regelmenge, da keine weitere Unterteilung nach verschiedenen Zwecken vorgenommen werden muß. Durch die Spezifikation des Charakters über variable Schriftarteigenschaften ergibt sich aber eine sehr große Menge möglicher Schriftarten, aus der eine ausgewählt werden muß.
Bei einer näheren Betrachtung zeigt sich, daß beide Arten ein Schriftbild festzulegen, inadäquat sind, da sie eine überaus starke Strukturierung der Regelmengen erfordern. Besser ist eine Kombination beider Methoden, da die einzelnen Schriftarten sowohl anhand bestimmter Merkmale klassifiziert als auch den Zwecken mit geeigneten Gewichtungsfaktoren zugeordnet werden können.
Die erwünschten Wirkungen können in Einzelwirkungen bzgl. der klassifizierten Merkmale zerlegt werden, und man kann dann durch eine spezielle Verknüpfung dieser Tupelmengen (Bevorzugung bzw. Streichung einzelner Tabelleneinträge) das gewünschte Schriftbild erhalten.
3.3.2 Darstellung der typographischen Implikationen
Die Abhängigkeiten der einzelnen typographischen Eigenschaften voneinander können graphisch dargestellt werden. In der folgenden, hierarchisch aufgebauten Grafik sind alle Eigenschaften, die eine Auswirkung auf ein harmonisches Bild haben, zusammen mit ihren gegenseitigen Wechselwirkungen und Einflußmöglichkeiten enthalten.
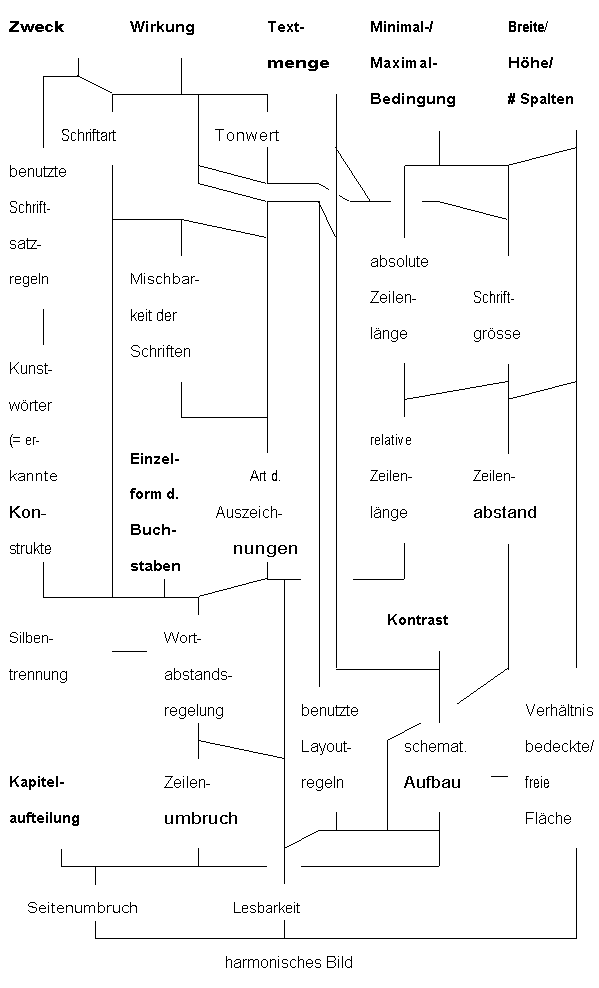
Abb. 3.11: Regelabhängigkeiten
Das Netzwerk ist von oben nach unten zu lesen. Dabei bedeutet ein Pfad von oben nach unten, daß die darunterliegenden Eigenschaften von den darüberliegenden abhängen. Die Pfade dürfen nur absteigend durchlaufen werden. Die durch eine verfettete Darstellung markierten Knoten symbolisieren Angaben, die vom Benutzer oder dem Text selbst beeinflußt werden können. Die Art der Abhängigkeit (proportional, umgekehrt proportional, usw.) ist in diesem Netzwerk nicht enthalten.
Diese Hierarchie muß bei der Entwicklung einer Regelmenge für das Layout (s. Kap. 3.4.8) derart berücksichtigt werden, daß der Reihenfolge der Regelanwendung diese Hierarchie zugrunde liegt. Regeln, die auf den unteren Hierarchiestufen liegen, dürfen erst später zur Anwendung kommen und demnach nur auf höher gelegene Einträge zurückgreifen.
3.3.3 Aufbau der Wissensbasis für die Wirkungen
Wie oben schon erwähnt, sollen einige Parameter über natürlichsprachliche Begriffe eingestellt werden können. Davon konkret betroffen sind die Wirkungen, die ein Text auf den Leser ausüben soll. Zum Beispiel soll unter der Angabe "kontrastreich" eine Auszeichnungsform gewählt werden, die im hohen Kontrast zu dem übrigen Text steht (z.B. Verfettung bei einer nicht verfetteten Schriftart), im Gegensatz zu "kontrastarm" (z.B. Sperrsatz oder Unterstreichung bei einer nicht verfetteten Schriftart). Andere Beispiele sind eine leichte Verringerung des Zeilenabstandes (Durchschuß), wenn ein kompakteres Schriftbild erzielt werden soll, und Wahl einer Schriftart mit einer geringen Strichdicke bzw. keine Verfettung des Schriftbildes bei einer "grazilen" Wirkung des Textes.
Mit der Eingabe einer Wirkung ist gemeint, die einzelnen Parameter, die ein Desktop-Publishing-System zur Verfügung stellt, so einzustellen, daß der Text genau die gewünschte Wirkung auf den Leser ausübt. Dabei kann eine Wirkung sehr einfach oder aber kompliziert aufgebaut sein. Bei einem einfachen Aufbau ist direkt nur ein Parameter betroffen (z.B.: "serifenbetont" bedeutet die Auswahl einer Schriftart mit ausgeprägter Serifenbildung), während bei einem komplizierten Aufbau mehrere Parameter betroffen sind (z.B.: "statisch" bedeutet fixed-Modus, Flattersatz und eine aufrechte Schriftart (nicht kursiv)).
Die Wirkungen (Globalwirkungen) werden im Klartext eingegeben (z.B. "Wirkung dezent"), wobei schon bei der Eingabe erste Widersprüche entdeckt werden. Das ist z.B. der Fall bei den widersprüchlichen Eingaben "Wirkung dynamisch" und "Wirkung statisch". Sobald eine der beiden eingegeben wurde, besteht nicht mehr die Möglichkeit, die andere zusätzlich einzugeben. (Zwei Eingaben sind dann widersprüchlich, wenn sie genau entgegengesetzte Parametereinstellungen bewirken sollen.)
Nachdem einzelne (Global-)Wirkungen eingegeben worden sind, werden diese anhand entsprechender Regeln (Tabelle) in Einzelwirkungen mit entsprechenden Werten (Parametereinstellungen (s.u.)) übersetzt. Diese Art der Unterteilung bietet sich auf Grund der Struktur der Wirkungen (s. o.) an. Dabei kann es passieren, daß zwei Globalwirkungen eingegeben worden sind, die sich in manchen Einzelwirkungen widersprechen. In diesem Falle würde dem Benutzer dann aber ein entsprechendes Menü angeboten, aus dem er sich die Angabe heraussuchen kann, die seinen Wünschen am ehesten entspricht.
Um den Minimalanforderungen für eine Datenbasis im Bereich des Desktop-Publishings zu genügen, müssen folgende Einzelwirkungen vorhanden sein:
· Tonwert (hell - dunkel)
· Kontrast (klein - groß)
· Proportionalschrift (fixed - proportional)
· Blocksatz (Flattersatz - Blocksatz)
· Kursivschrift (links-kursiv - gerade - rechts-kursiv)
· Verfettung (normal - halbfett - fett)
· Strichdicke (dünn - dick)
· Zeilenabstand (Absolutangaben)
· Schriftgröße (Absolutangaben)
· Serifenbetonung (keine - starke)
· Konturausprägung (mager - fett)
·
Schriftart (möglichst nicht erwünscht - favorisiert)
[wird durch die Zweckangabe eingetragen]
· Auszeichnung
Mit Ausnahme der letzten beiden Einträge können jeder Einzelwirkung folgende Werte zugeordnet werden:
1. ein bestimmter Grundwertebereich:
Der Grundwertebereich ist in drei Teilbereiche unterteilt und gibt an, welchen Wert die entsprechende Einzelwirkung besitzen sollte:
· alles (gesamter Bereich)
· niedrig (der untere Teilbereich)
· mittel (der mittlere Teilbereich)
· hoch (der obere Teilbereich)
2. eine Ausprägung des Grundwertebereiches, falls eine genauere Angabe innerhalb des Grundwertebereiches notwendig ist:
· unten
· Mitte
· oben
· total
3. eine Suchrichtung:
Die Suchrichtung gibt an, in welcher Richtung des Grundwertebereiches weitergesucht werden soll, falls sich dort kein geeigneter Wert finden läßt:
· plus (nach oben)
· minus (nach unten)
· null (keine weitere Suche)
· beide (in beide Richtungen)
Sollte direkt aus dem entsprechenden Grundwertebereich kein geeigneter Wert herausgesucht werden können, so muß in Abhängigkeit von der Suchrichtung über Backtracking ein Wert gefunden werden können.
Der Vorteil dieser Wertzuweisungsart besteht in einer unscharfen Wertzuordnung, da jeder Wert, der in den angegebenen Grundwertebereich abgebildet wird, genommen werden kann. Darüber hinaus ist eine Suche nach weiteren Werten, falls die derzeitigen nicht passen sollten, über diese Abbildungsfunktion und nicht über die Reihenfolge der Einträge in die Tabelle spezifiziert.
Je nach Art der Einzelwirkung findet eine lineare (z.B. Tonwert) oder eine nicht stetige (z.B. Blocksatz) Übersetzung statt.
Der o.a. Aufbau der Wissensbasis gestattet es, die Anzahl der erfaßten Eigenschaften später noch zu erhöhen. Denkbar wäre eine Veränderung der Wissensbasis bzgl. folgender Punkte:
· die Aufnahme einer Eigenschaft, die die Ausschmückung einzelner Buchstaben angibt (z.B. für Initiale),
· die vorhandenen Einträge gemäß anderen Anforderungen neu einstellen (anders bewerten),
· anstelle einer Dreiteilung des Grundwertebereiches eine weitere feinere Unterteilung vornehmen,
· die Aufnahme neuer Globalwirkungen und damit
· eine Gruppierung der Wirkungen bei einer weiteren Erhöhung der Anzahl der Globalwirkungen.
3.3.4 Festlegung einzelner Dokumentenklassen
Die Dokumentenklassen unterscheiden sich in ihrem Zweck, ihren Anforderungen und ihrem Aufbau, so daß sich folgende minimale Unterteilung, die aber dennoch weiter ausgedehnt und individuell angepaßt werden kann, als geeignet erwiesen hat:
· Broschüre: Informationstext mit einem aktuellen Bezug;
· Informationstext: kurzer Text mit einem hohem Informationsgehalt;
· Handzettel: sehr wenig Text, der durch große Lettern sofort auffallen muß;
· Zeitungsartikel, -schrift: Text mit einem charakteristischen Aufbau;
· Brief: Text mit einem anderen charakteristischen Aufbau
· Lesetext: sehr große Textmenge, die ohne Ermüden gelesen werden können sollte;
· Sachtext: evtl. große Textmenge, auf die sich der Leser relativ stark konzentrieren muß.
Für die einzelnen Dokumentenklassen lassen sich zuerst verschiedene Schriftarten mit verschiedenen Prioritäten festlegen, die das System dann mit absteigender Priorität durchrechnet. Weiter lassen sich in Abhängigkeit von einzelnen Dokumentenklassen z.T. Regeln für das Layout angeben, die unbedingt bzw. gar nicht zur Berechnung herangezogen werden müssen. Eventuell hat sogar die Dokumentenklasse rückwirkend einen Einfluß auf den Schriftsatz, da nicht alle Grammatiken für alle Dokumentenklassen berücksichtigt werden müssen.
3.3.5 Klassifizierung der Schriftarten
Damit der Computer einzelne Schriftarten handhaben kann, müssen diese klassifiziert werden.
Dabei bietet sich eine Unterteilung nach folgenden Kriterien an: (/Nerdinger 84/)
- Größe der Buchstaben
- Neigung der Buchstaben (Kursivschrift)
- Betonung und Ausbildung der Serifen
- Strichstärke bzw. Wechsel der Liniendicke (horizontal/ vertikal)
Weiterführend können zusätzlich folgende Kriterien herangezogen werden:
- Breitenverhältnis der einzelnen Buchstaben zueinander
- Höhe der Ober- und Unterlängen, d.h. nach der Verwendung des Leitliniensystems
- Buchstabenaufbau (Form und Gestaltung der Buchstaben)
- Grad der Ausschmückung der einzelnen Buchstaben
Darüber hinaus kann in der Regelmenge für das Layout noch Wissen enthalten sein, wozu eine Schriftart in Bezug auf den Zweck und die erwünschten Wirkungen (nicht) verwendbar ist und welcher Charakter einer Schriftart zugeordnet werden kann.
3.3.6 Festlegung der Formate
Bei der Festlegung des Papierformates kann das System dem Benutzer nicht sonderlich behilflich sein, wohl aber bei der Berechnung des Satzspiegels. Die Größe des Blattes, das bedruckt werden kann, muß durch den Benutzer vorgegeben werden, da das System darauf keinen Einfluß hat. Schwieriger gestaltet sich schon die Auswahl bzw. die Berechnung des Satzspiegels, d.h. die Größe und die Position der bedruckbaren Fläche. Auf der einen Seite existieren Randbedingungen, die eine Wahl einschränken; dazu gehören z.B. Minimal- und Maximalangaben für die Anzahl der Seiten, die das System zur Verfügung hat. Auf der anderen Seite darf das System die Regeln, die für einen gut gewählten Satzspiegel berücksichtigt werden müssen, nicht außer acht lassen. Eine dieser Regeln ist der "Goldene Schnitt", der besagt, wie groß die bedruckbare Fläche auf dem Blatt Papier sein darf und wie diese positioniert werden muß, damit das Erscheinungsbild optisch ausgewogen ist. Sofern der Benutzer keine Angaben über einen Satzspiegel gemacht hat, kommt diese Regel zur Anwendung.
Durch eine Implementierung des Algorithmusses zur Formatfestlegung in Regelform besteht die Möglichkeit, dem Benutzer eine funktional höherwertigere Eingabe zu präsentieren: Er kann dann z.B. das Verhältnis vom linken zum oberen Rand definieren. Sobald einer von beiden Werten bekannt ist, wird der andere automatisch - über eine entsprechende Regel - berechnet. Diese Form der Berechnung geschieht iterativ solange, bis alle Werte bekannt sind. Sollte ein Wert fehlen, so kann dieser bspw. über den "Goldenen Schnitt" ermittelt werden. Aus der gesamten Regelmenge kommen nur diejenigen Regeln zur Anwendung, die einen noch fehlenden Wert berechnen, damit eine doppelte Berechnung eines Wertes, der evtl. mit dem ersten nicht übereinstimmt, nicht stattfindet.
Eine Faustregel zur Ermittlung der Satzspiegelproportionen für den Goldenen Schnitt ist das Ziehen von Diagonalen über die Einzel- bzw. Doppelseite. Zu einer gegebenen Satzspiegelbreite läßt sich so leicht die entsprechende Höhe ablesen. Die Proportionen der Papierränder sind allerdings bei dieser Art der Ermittlung variabel und nicht absolut dem Goldenen Schnitt entsprechend:
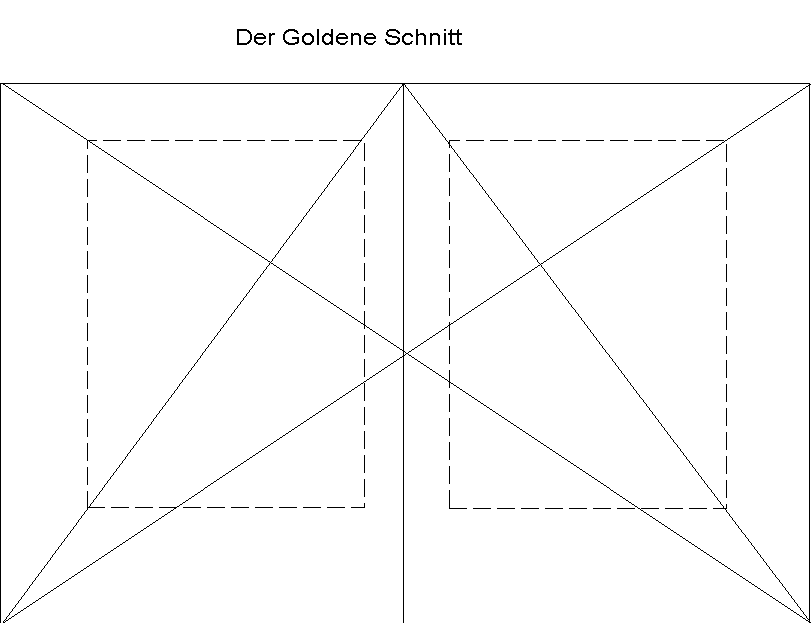
Abb. 3.12: Ermittlung der Ränder gemäß dem Goldenen Schnitt
3.3.7 Verteilung der Zeilenenden
Zur optimalen Verteilung der Zeilenenden muß zuerst die fontspezifische Wortlänge und dann die bestmögliche Verteilung der Leerstellen unter Berücksichtigung der Silbentrennung und der aktuellen Zeilenlänge berechnet werden.
3.3.7.1 Berechnung der korrekten Wortlänge
Um die Zeilenenden optimal verteilen zu können, muß der Platz berechnet werden, den ein Wort auf dem Blatt Papier einnimmt:
1. Die genaueste Berechnung der Wortlänge legt die exakte Breite jedes einzelnen Buchstabens zugrunde. Dazu ist aber eine sehr große Datenmenge erforderlich, deren Speicherung am besten dreidimensional erfolgt: Bei Vergrößerung der Schriftgröße ergibt sich eine nichtlineare Vergrößerung der einzelnen Buchstaben, sowohl im Verhältnis untereinander als auch zur Schriftgröße. Das bedeutet, daß die Datenbasis für jedes einzelne Zeichen (ca. 80 Stk.) jeweils einen Eintrag für eine Schriftart (Roman, Helvetic, Gothic), eine Schriftgröße (8 - 12pts) und ein Attribut (2 Stk.), d.h. weit über 2000 Einträge enthalten müßte. Diese Tabellen sind als Druckertreiber in allen gängigen Textverarbeitungs- und DTP-Programmen enthalten und sollen hier nicht noch einmal realisiert werden. (Die ästhetischen Aspekte (s.u.) werden bei der Beschreibung aller weiteren Möglichkeiten ebenfalls nicht weiter berücksichtigt.)

Abb. 3.13: exakte Berechnung der Wortlänge
2. Die zweitbeste Berechnung der Wortlänge stützt sich auf die Annahme, daß die Breite jedes einzelnen Buchstabens linear mit der Schriftgröße anwächst. Deshalb muß zusätzlich zu dieser zweidimensionalen Tabelle für jede einzelne Schriftart und für die einzelnen Schriftgrößen ein Vergrößerungsfaktor abgespeichert werden.

Abb. 3.14: fast exakte Berechnung der Wortlänge
3. Die nächstbeste Berechnung der Wortlänge, die zwar nicht schneller, dafür jedoch nicht so speicherintensiv ist, beruht auf der Zuordnung der einzelnen Buchstaben zu "Breitenmengen" (jeder Buchstabe bekommt eine Grobeinteilung in eine relative Breite (schmal, mittel, breit)). Da genau wie bei 1. und 2. die einzelnen Buchstaben berücksichtigt werden, ist die unter 2. beschriebene Methode dieser vorzuziehen. Die Speicherung erfolgt ebenfalls zwei- oder dreidimensional:
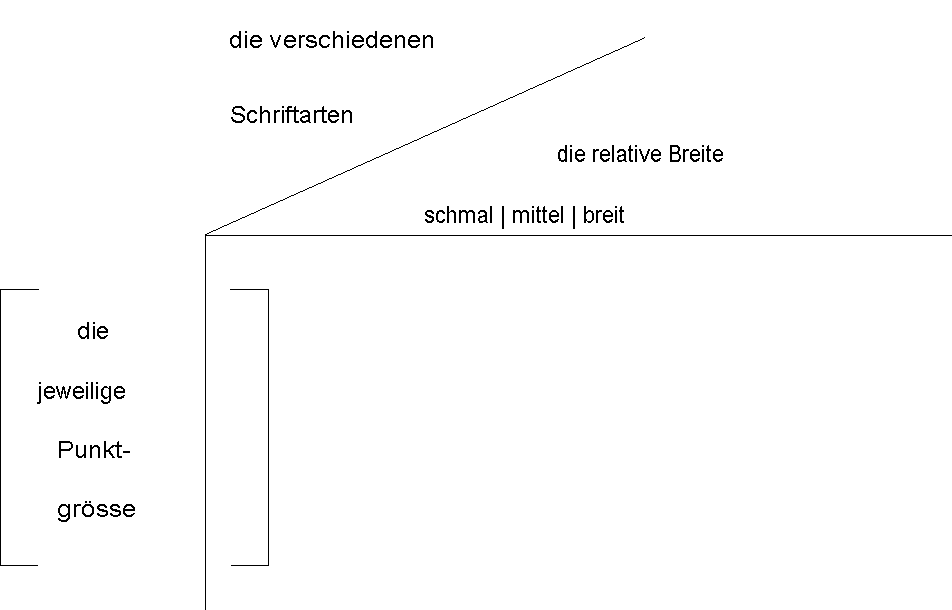
Abb. 3.15: platzsparende, halbwegs exakte Berechnung der Wortlänge
4. Die einzige Berechnung der Wortlänge, die zwar ungenau, aber noch in PROLOG implementiert werden kann, ohne daß das System zu langsam wird, benutzt die durchschnittliche Buchstabenbreite innerhalb eines Fonts. Eine leichte Verbesserung des Ergebnisses läßt sich erzielen, wenn bei der Berechnung der durchschnittlichen Buchstabenbreite die einzelnen Buchstaben gemäß ihrem Vorkommen in der jeweiligen Sprache gewichtet werden. Hierbei wird zur Speicherung der benötigten Daten nur ein zweidimensionales Array verwendet:

Abb. 3.16: leicht realisierbare Berechnung der Wortlänge
Damit bei der Berechnung der Wortlänge ästhetische Aspekte exakt berücksichtigt werden können, müßte darüber hinaus die Datenbasis noch um weitere spezielle Einträge ausgedehnt werden. In der Auflistung der Lösungsmöglichkeiten ist ebenfalls die Problematik des Kernings und der Ligaturen noch nicht enthalten:
1. Bestimmte Buchstabenkombinationen werden als eine Einheit betrachtet (Ligaturen) oder aber bei einem Zusammentreffen unterschnitten (Kerning). Für jeden einzelnen Buchstaben müssen dazu 4 Werte bereitgestellt werden, die die Weite der Unterschneidung angeben:
- left-side height kerning-value
- right-side height kerning-value
- left-side n-height kerning-value
- right-side n-height kerning-value
Damit z.B. der Buchstabe 'a' von rechts unter den Buchstaben 'T' geschoben werden kann, muß sowohl der left-side height kerning-value von 'a' als auch der right-side n-height kerning-value von 'T' positiv sein. Der Minimalwert von beiden gibt dann die Weite der Unterschneidung an.
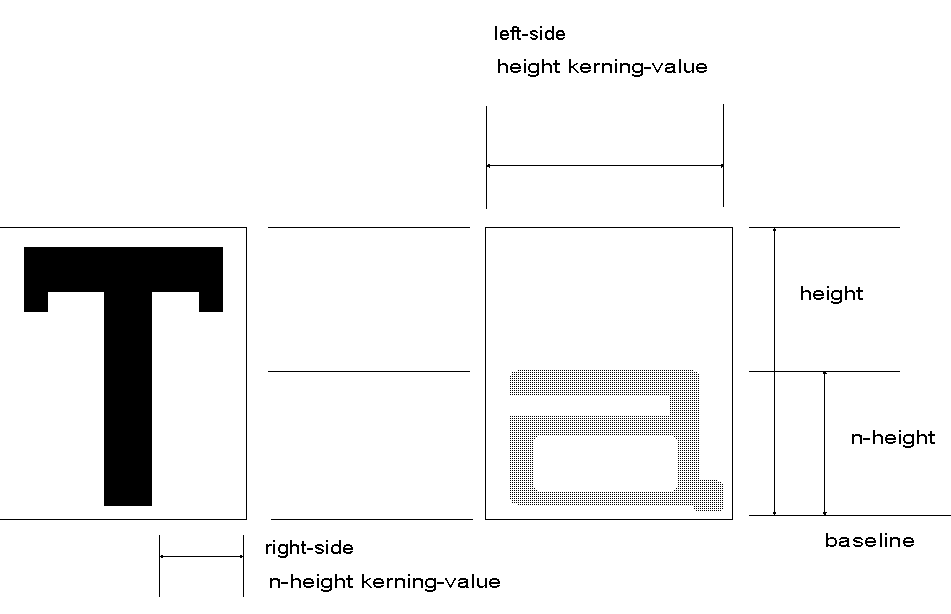
Abb. 3.17: Beispiel des Kernings zweier Buchstaben
Zusätzlich zur Breite muß bekannt sein, wann derartige Buchstabenkombinationen als Ligatur oder als Kerning zu behandeln sind: schaffen, erfinden, abflauen;
aber: Kaufleute, Schilfinsel, Rohstofffrage
2. Die Wortzwischenräume müssen entsprechend den aufeinandertreffenden Buchstaben optisch ausgemittelt werden, d.h. je nach Buchstabenform weiter auseinander oder enger zusammen: ineinandergreifende Buchstaben benötigen weniger Zwischenraum als zwei senkrechte Buchstaben.
3. Um eine ausgeglichene Seitenbegrenzung (optisch gleich lange Zeilen - Blocksatz) zu erhalten, müssen die Buchstaben der Zeilenanfänge und der Zeilenenden je nach ihren Formteilen etwas ein- oder ausgerückt werden (s. auch Punkt 2.), wodurch sich leicht unterschiedliche Zeilenlängen ergeben. Wie weit dieses Ein-/Ausrücken geschehen soll, wird durch den left-(right-)column-side adjustment-value des betreffenden Buchstabens, der an dem entsprechenden Spaltenrand zu stehen kommt, angegeben.
4. Kursiv dargestellte Buchstaben benötigen einen zusätzlichen Platzausgleich, falls der folgende bzw. vorhergehende Buchstabe nicht mehr kursiv ist, damit sich der Buchstabenabstand optisch nicht ändert. Jeder Font besitzt für jeden Buchstaben einen derartigen Korrekturwert, der mit dem Grad der Kursivität (italicizing) multipliziert werden muß:
· left-side italic-correction factor
· right-side italic-correction factor
Der resultierende Kasten ("Box"), der sich aus allen derartigen Angaben ergibt, ist in der folgenden Graphik dargestellt:
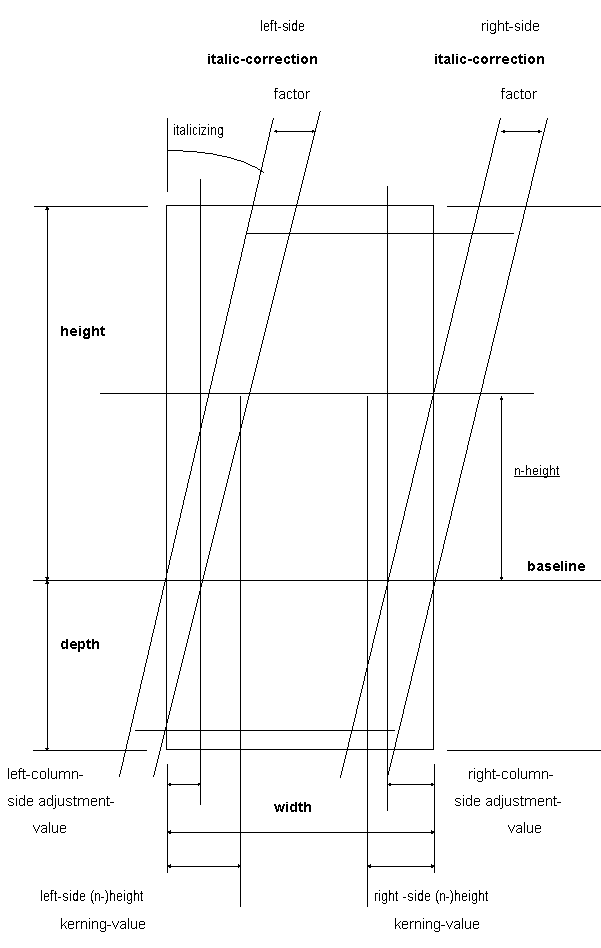
Abb. 3.18: Kasten (box) für einen einzelnen Buchstaben
Wie die einzelnen Buchstaben zu behandeln sind, wie weit sie ein- oder ausgerückt werden müssen, kann leicht einer Tabelle entnommen werden. Wann eine derartige Behandlung zu erfolgen hat (das betrifft besonders den Punkt 1 (Ligaturen)), kann nicht mehr in einer Tabelle gespeichert werden, da diese dann zu groß wird. Besser ist eine Behandlung dieser Problematik in Verbindung mit der Silbentrennung (Kap. 3.3.7.4), da diese ohnehin Wissen über einzelne Wörter und deren Aufbau enthält.
3.3.7.2 Berücksichtigung von Satzzeichen
Damit die Satzzeichen jeweils hinter dem vorhergehenden Wort gedruckt werden können, ist es einfacher, diese über eine spezielle Tabelle dem vorhergehenden Wort zuzuordnen und dann beim Ausdruck abzufragen. Diese Vorgehensweise ist bei der Programmierung transparenter und später in der Ausführung schneller, da der Unifikationsalgorithmus des PROLOG-Interpreters ausgenutzt werden kann und keine zusätzliche Rekursion durchgeführt werden muß.
3.3.7.3 Blocksatz
Die Implementierung des Blocksatzes erfolgt über das Mitzählen der Anzahl der Leerstellen in einer Zeile und anschließender Verteilung des restlichen zur Verfügung stehenden Platzes auf diese Leerstellen. Zur Speicherung der berechneten durchschnittlichen Leerstellenbreite wird eine eigene Tabelle erstellt, die für jede zu druckende Zeile diese Breite enthält. Anstelle des Druckes einer Leerstelle wird beim Ausdruck die Druckposition um diese Breite weitergesetzt - was z.B. bei einem Laserdrucker möglich ist.
Da die Wortlänge bei diesem System nur näherungsweise berechnet wird, kann es passieren, daß bei einer Zeile mit Wörtern, die relativ viele breite Buchstaben enthalten, der benötigte Platz unterschätzt und damit die Zeile insgesamt zu lang wird und umgekehrt. Das Resultat ist folglich ein nur teilweise ausgeglichener Flattersatz.
3.3.7.4 Silbentrennung
Zur Silbentrennung stehen prinzipiell mehrere verschiedene Ansätze zur Verfügung:
1. Regelbasierte Silbentrennung:
Für eine Implementierung in PROLOG<$IPROLOG> ist eine rein regelbasierte Lösung geeignet: sie ist schneller als die beiden anderen Lösungen, dafür aber relativ unsicher. Zusätzlich entsteht noch die Problematik des Aufbaus einer geeigneten Regelmenge.
2. Lexikonbasierte Silbentrennung:
Diese Lösung bietet sich für prozedurale Programmiersprachen an: Durch eine baumartige (z.B. B-Baum) Verwaltung aller Wörter ergibt sich eine trenngenaue und sehr schnelle Silbentrennung. Der Nachteil wird in der sehr großen Datenmenge deutlich, die bei diesem Verfahren gespeichert werden muß und daher nicht mehr mit vertretbarem Zeitaufwand durch den PROLOG-Interpreter gehandhabt werden kann.
3. Musterbasierte Silbentrennung:
Das System TEX (/Knuth 86a/) benutzt dieses Verfahren, das Frank M. Liang in seiner Dissertation erarbeitet hat, um eine sehr hohe Trenngenauigkeit (über 95 % unter Berücksichtigung der Worthäufigkeit) zu erreichen: Dem Programm sind ca. 4400 Buchstabenmuster unterschiedlicher Länge mit den dazugehörigen Trennvorschlägen bzw. -verboten und deren Erwünschtheit ("desirability") bekannt. Das zu trennende Wort wird in alle möglichen Unterwörter zerlegt, die dann mit den Mustern verglichen werden. Der maximal vorkommende Erwünschtheitswert für eine bestimmte Stelle gibt dann an, ob das Wort dort getrennt werden kann oder nicht. Dieses Verfahren ist aufgrund der hohen Anzahl von Rechenschritten zur Berechnung des Ergebnisses für eine Implementierung in PROLOG nicht geeignet. Dieses Verfahren findet zwar nur 89.3 % aller möglichen Trennstellen, dafür werden aber keine zusätzlichen falschen Trennstellen angegeben.
Eine Kombination der beiden ersten Verfahren leistet (bei einer Implementierung in PROLOG) das Gewünschte: bei einer silbenorientierten Vorgehensweise werden die Worte ohne allzugroßen Zeit- und Speicheraufwand getrennt, d.h. bei dem zu trennenden Wort werden zuerst die bekannten Vor- und Nachsilben rekursiv abgetrennt. Danach wird auf das verbleibende Wortmittelteil ein regelbasiertes Verfahren angewendet, das phonetische Muster (Vokale und Konsonanten) berücksichtigt.
Der Algorithmus zur Silbentrennung kann auch für die Erkennung verwendet werden, wann eine Buchstabenkombination als Ligatur behandelt werden darf (muß) und wann nicht, denn die Informationen, die dafür eine Rolle spielen, sind indirekt in diesem Algorithmus enthalten: Zwei Buchstaben können als Ligatur verwendet werden, falls diese innerhalb einer Silbe vorkommen.
Solange es nicht möglich ist, bei der Silbentrennung die Semantik zu berücksichtigen, wird (auch mit einem lexikonbasierten Verfahren) keine 100%ige Trenngenauigkeit erreicht werden können. Das läßt sich leicht an zwei kleinen Beispielen verdeutlichen, die durch Wortzusammensetzungen entstehen:
1 Wachs-tube Û Wach-stube
2. Bet-tuch Û Bett-tuch
Je nach der Bedeutung, die ein Wort in einem bestimmten Kontext hat, muß es unterschiedlich getrennt werden.
3.3.7.5 Badness und Glue
Die Steuerung der Buchstabenverschiebung über die Zeilenenden hinweg müßte ein "Wertebereich" übernehmen, den Donald E. Knuth (/Knuth 86a/, Kap. 6 und Kap. 14) mit Badness bezeichnet: Gemeint sind damit fontspezifische Zahlenpaare, die angeben, wie weit zwei Wörter mindestens auseinander stehen müssen bzw. höchstens stehen dürfen. (Ausgenommen von dieser Regelung sind natürlich Zeilen mit einzelnen Worten, die nicht durch Silbentrennung aufgefüllt werden können.) Dieser Badness-Wert bedingt, daß nicht aus der vorhergehenden bzw. nachfolgenden Zeile allein eine genügende Anzahl von Buchstaben genommen werden kann, sondern rekursiv alle weiteren benachbarten Zeilen berücksichtigt werden müssen.
Im Rahmen dieses Systems ist jedoch nur eine Verschiebung einzelner Zeilen möglich, da eine Neuberechnung der Verteilung der Zeilenenden in PROLOG zu rechenintensiv und damit zu zeitaufwendig ist.
In dem von Donald E. Knuth entwickelten System TEX wird dieser Badness-Wert benutzt, um die Zeilenenden optimal zu verteilen. Den Leerstellen zwischen den einzelnen Worten wird zusätzlich ein Zahlentripel (D.E. Knuth nennt es "Glue") zugeordnet, das angibt, wie breit die Leerstelle im Normalfall sein soll und wie weit diese ausgedehnt bzw. verkürzt werden kann, falls dies erforderlich wird. Bei einer erforderlichen Ausdehnung des Wortzwischenraumes werden alle Zwischenräume einer Zeile dem "Glue"-Wert entsprechend anteilig ausgedehnt. Nach einem Komma wird der Wortzwischenraum um den Faktor 1,25 und nach einem Punkt um den Faktor 3 zusätzlich zu dem "Glue"-Wert vergrößert. Die hieraus ersichtlichen Probleme liegen in der Erkennung derartiger Zeichen: Bei TEX müssen die richtigen Steuersequenzen per Hand eingegeben werden, damit der "Glue"-Wert korrekt gesetzt werden kann; das hier beschriebene System erkennt selbständig einzelne Konstrukte und setzt diese entsprechend um (vgl. Kap. 2).
3.3.7.6 Berücksichtigung besonderer Wörter
Bei bestimmten Konstrukten, die anhand der Syntaxdiagramme erkannt worden sind, müssen noch folgende Besonderheiten bei der Verteilung der Zeilenenden beachtet werden:
1. Austauschen gegen eine andere Form desselben Konstruktes, falls es das letzte Wort in der Zeile ist,
2. Austauschen gegen eine andere Form desselben Konstruktes, falls es das erste Wort in der Zeile ist,
3. es darf nicht als erstes Wort in der Zeile vorkommen,
4. Austauschen gegen eine andere Schreibweise (Alternative).
Zu 1.: Bestimmte Wörter müssen ausgetauscht werden, falls sie bei der Verteilung der Zeilenenden als jeweils letztes Wort in der Zeile stehen würden:
Bsp.: 100,- - 200,- DM
Falls "100,-" als letztes Wort in der Zeile steht, muß es gegen "100,- DM" ausgetauscht werden. Da diese Wörter in der Regel durch längere Wörter ersetzt werden, ist es sehr wahrscheinlich, daß diese dann gar nicht mehr in die Zeile passen und demnach komplett in die nächste Zeile, dann aber wieder in der kurzen Form, übernommen werden müssen.
Zu 2.: Genau wie unter 1. gibt es Wörter, die nicht am Zeilenanfang stehen dürfen:
Bsp.: 100,- - 200,- DM
Falls "-" am Zeilenanfang stehen sollte, muß es gegen "bis" ausgetauscht werden. Ein derartiger Austausch ist im Gegensatz zu 1. problemlos möglich, da noch genügend Platz innerhalb dieser Zeile vorhanden ist.
Zu 3.: Laut Auskunft der Sprachberatungsstelle der Dudenredaktion gibt es "... keine Duden-Regel, die den Gedankenstrich am Zeilenanfang oder -ende ausdrücklich verbietet. Aus Gründen der Lesbarkeit empfiehlt es sich aber, zumindest den einzelnen Gedankenstrich ... und den zweiten Gedankenstrich eines Gedankenstrichpaares ... nicht an den Zeilenanfang zu setzen. In der Praxis wird nach unseren Beobachtungen allgemein nach dem Grundsatz 'Ein Gedankenstrich sollte nicht am Anfang einer Zeile stehen' verfahren."
Diese Gedankenstriche sollten daher, sofern dies problemlos möglich sein sollte, an das Ende der vorhergehenden Zeile gesetzt werden. Falls dieses nicht möglich ist, so ist das vorhergehende Wort einfachheitshalber zu trennen und der zweite Wortteil an den Anfang dieser Zeile zu setzen.
Zu 4.: Bestimmte Konstrukte, die falsch geschrieben worden sind, können auf mehrere Arten korrekt dargestellt werden. Ein Beispiel dazu ist die Umwandlung von "sechshundert DM" in "600,- DM" oder "sechshundert Deutsche Mark". Welche der beiden Alternativen endgültig verwendet wird, hängt u.a. von der Textmenge und der Stellung innerhalb der Zeile ab.
Diese o.g. Besonderheiten treten bei folgenden Konstrukten auf:
1. Währungen und
2. Gedankenstrichen.
3.3.8 Verteilung der Spaltenenden
Zur Verteilung der Spaltenenden muß nicht nur der Zeilenabstand einschließlich eventuell vorhandener Fußnoten allein berücksichtigt werden, sondern auch ästhetische Aspekte, wie z.B. Schusterjungen und Hurenkinder.
3.3.8.1 Konfliktauflösung bei Schusterjungen und Hurenkindern
Um das Phänomen des Schusterjungen zu beheben, müssen die entsprechenden Zeilen auf die nächste Seite verschoben werden. Damit ergibt sich eine nicht ganz gefüllte Seite und automatisch eine Verschiebung aller Zeilen nach hinten, was im Extremfall ein oder mehrere neue Hurenkinder bzw. Schusterjungen erzeugt und alte löscht. Genau entgegengesetzt muß bei der Problemlösung für ein Hurenkind verfahren werden: Die letzten Zeilen des Absatzes müssen auf die vorhergehende Seite, was zu viele Zeilen auf diese plaziert und evtl. neue Schusterjungen erzeugt, oder noch mehr Zeilen müssen auf die Folgeseite, was die Vorseite etwas leert und evtl. wiederum neue Hurenkinder erzeugt.
Die Lösung des Problems liegt keinesfalls in der Verschiebung einzelner Zeilen, wie es von fast allen Textverarbeitungs- und DTP-Programmen gemacht wird, da auf diese Art das gesamte Bild des Textes zerstört wird. Optimal wäre eine Neuverteilung der Zeilenenden derart, daß durch eine Verschiebung einzelner Buchstaben über die Zeilenenden und ggf. über Seiten hinaus die Anzahl der Zeilen erhöht wird und die einzelnen Zeilen durch größere Leerräume so weit wie möglich aufgefüllt werden. Dadurch wird erreicht, daß alle Seiten die gleiche Anzahl von Zeilen aufweisen.
Des weiteren sollten keine Algorithmen gewählt werden, die den Text in zwei Richtungen verschieben, da sie sich im Extremfall aufheben: Besser geeignet ist ein Algorithmus mit einer Expansion des Textes ausschließlich nach hinten, wobei bei Entdeckung eines Schusterjungen oder Hurenkindes der Inhalt der vorhergehenden Seite als Ausgleich verwendet werden kann.
Die Problematik der Schusterjungen und Hurenkinder wird in TEX dergestalt berücksichtigt, daß eine Zeile niemals allein auf einer Seite steht. Die zweite bzw. die letzte Zeile eines Kapitels wird mit der vorhergehenden zu einer Einheit verbunden, so daß dann immer zwei Zeilen zusammen auf einer Seite stehen. Da der Computer aber nicht genügend Hauptspeicher hat, um mehrere Seiten zu behalten, "... TEX simply chooses each page break as best it can, by a process of local rather than global optimization." (/Knuth 86a/, S. 110)
3.3.8.2 Fußnoten und Anmerkungen
Bei der schreibtechnischen Darstellung von Fußnoten sind folgende Richtlinien zu beachten: (/Duden DT21/, S. 128)
- Die Fußnote wird durch zwei Leerzeilen oder eine engzeilige Leerzeile mit einem Strich über ein Drittel der Spalte vom übrigen Text abgesetzt.
- Die Fußnotenzahl wird hochgestellt und zwei Zeichen eingerückt.
- Alle Zeilen des Fußnotentexts werden drei Leerstellen eingerückt und einzeilig gedruckt.
- Mehrere Fußnoten werden untereinander durch eine halbe Leerzeile voneinander abgesetzt.
- Jede Fußnote beginnt wie ein normaler Satz mit Großschreibung und endet mit einem abschließenden Satzzeichen.
- Fußnoten, Endnoten und Anmerkungen, die am Fuß der Spalte stehen, werden so plaziert, daß sie vertikal höchstens die Hälfte der Spalte einnehmen. Sollte der Platz für eine Fußnote nicht mehr ausreichen, so ist der Text auf die nächste Seite zu übernehmen und bei der Verteilung der Spaltenenden entsprechend zu berücksichtigen.
Eine automatische Vergabe der Nummern bewirkt eine korrekte Zählung, auch wenn noch nachträglich einzelne Fußnoten in den Text eingefügt worden sind.
3.3.8.3 Berücksichtigung besonderer Wörter
Genau wie in Kap. 3.3.7.6 beschrieben, existieren auch bei der Verteilung der Spaltenenden besondere Wörter, die einer gesonderten Behandlung bedürfen:
1. Dazu zählen mehrere Leerzeilen zwischen zwei Absätzen, die zufällig an den Anfang einer Spalte geraten sind: Diese sind dann bei der Verteilung der Spaltenenden unberücksichtigt zu bleiben, damit kein unterschiedlich hoher oberer Rand entsteht.
2. Als weiterer Punkt sei in diesem Zusammenhang die Blockbildung eines ganzen Absatzes, der bspw. eine Grafik oder eine Tabelle darstellt, genannt. Dieser Absatz darf nicht über ein Spaltenende "verteilt" werden.
Darüber hinaus kann dieser "Graphikblock" einem "Textblock" referentiell zugewiesen werden, d.h., daß der Graphikblock innerhalb der Grenzen, die durch den Textblock vorgegeben sind, beliebig verschoben werden kann, so daß die einzelnen Seiten besser genutzt werden können. Als Folge dieser Verschiebung müssen Verweise, die auf die Graphik Bezug nehmen ("oben" bzw. "unten", "s.o." bzw. "s.u."), gegeneinander ausgetauscht werden, je nach dem wo der Graphikblock - von diesen Verweisen aus gesehen - positioniert wird.
3.3.9 Die Struktur des Textspeichers
Die Speicherung des Textes innerhalb dieses Systems geschieht, wie schon in Kap. 2.5.2 erwähnt, durch PROLOG-Fakten, die die einzelnen Wörter einschließlich ihrer Nummern enthalten. Durch die Wortnummer ergibt sich eine lineare Abspeicherung des Textes. In der folgenden Grafik ist diese Linearität durch die Abfolge der Wörter von oben nach unten verdeutlicht. Durch die Verwendung einer Wortnummer wird bei der Zuordnung der Besonderheiten des Textes zu den Wörtern im Prinzip eine doppeltverkettete Liste erzeugt:
|
|
v
wort i-2 Û
Zeilenende k Û
Seitenende m-1
| Û
Trennung: Teil1 + Teil2
|
v
wort i-1 Û
Zeilenanfang k+1 Û
Seitenanfang m
|
|
v
wort i Û
Satzzeichen l
|
|
v
wort i+1 Û
Konstrukt xy
| Û
Auszeichnung/Titel
.
.
|
v
wort j-1 Û
Zeilenende k+n Û
Seitenende m
|
|
v
wort j Û
Zeilenanfang k+n+1 Û
Seitenanfang m+1
|
|
v
Abb. 3.19: Struktur des Textspeichers
Die o.g. Indizierung einzelner Wörter mit den Wortnummern wird zur Zuordnung folgender Besonderheiten benutzt:
- Der Zugriff auf die nachfolgenden Satzzeichen wird durch die direkte Zuordnung wesentlich vereinfacht.
- Durch die Verteilung der Zeilenendesymbole ergibt sich über die Wortummer wiederum ein Verweis auf die Stellen, an denen sich das Zeilenende bzw. der Zeilenanfang befindet. Über diesen Verweis läßt sich eine weitere Strukturierung aufsetzen, die angibt, wie die einzelnen Zeilen auf die jeweiligen Seiten verteilt sind. (Ein weiterer Vorteil dieser eindimensionalen Textspeicherung besteht in der leichten Verschiebbarkeit der Zeilen- und Seitenendesymbole bei einer Neuformatierung.)
- Wenn das zugehörige Wort als ein besonderes Konstrukt erkannt worden ist, muß es evtl. bei der weiteren Verarbeitung des Textes getrennt behandelt werden.
- Da ausgezeichnete Textstellen und Titel anders gesetzt werden als der Rest des Textes - die Informationen über den Schriftsatz sind anderweitig gespeichert -, müssen die Textstellen nur gekennzeichnet werden.
Ein weiterer Vorteil dieser Indizierung liegt in der Variabilität der Schriftarteigenschaften: Es muß keine absolute Auswahl mehr getroffen ("Dieser Text soll unterstrichen sein!"), sondern nur eine relative Zuordnung zu einem besonderen Bezug ("Dieses Wort soll ein Schlagwort sein!") hergestellt werden. Nachdem der Text fertig editiert worden ist und alle Schriftarteigenschaften gemäß der vorhandenen Regeln ausgewählt worden sind, wird die endgültige Zuordnung referentiell getroffen.
3.3.10 Erfaßte Regelmenge
Über die o.g. Regeln werden folgende Angaben derzeit umgesetzt:
- Die Schriftgröße muß kleiner als der Zeilenabstand sein.
- Die Schriftgröße darf nicht so groß gewählt sein, daß keine vier Wörter zu je fünf Buchstaben ausgehend von der gewählten Schriftart mehr in die Zeile passen.
- Der Zeilenabstand sollte das 1,2 fache der Schriftgröße betragen.
- Bei den Zielgruppen Ältere und Jüngere/Kinder werden vorhandene Schriftgrößenangaben/ Zeilenabstandsangaben um ca. 10% vergrößert.
- Wenn bei den Zielgruppen Ältere/Jüngere keine Schriftgrößenangaben/Zeilenabstandsangaben vorhanden sind, wird als Sollgröße für die Schrift 11 Punkte angenommen.
- Die Schriftart wird passend zu Kontur- und Serifenangaben herausgesucht.
- Die Schriftarten werden nur mit der Verfettung angegeben (ausgewählt), wenn die vorgeschlagenen Schriftgrößen auf dem Drucker darstellbar sind.
- Der Blocksatz ist nur bei bestimmten Schriftarten erlaubt, nämlich bei Courier, Elite, Line Printer und allen Schriften in fixed-Modus.
- Mischbarkeit verschiedener Schriftarten.
- Unterschiedliche Darstellung der Titel verschiedener Stufen.
- Die Wirkungen werden in entsprechende Schriftarteigenschaften umgesetzt.
3.4 Bewertung der Ästhetik eines Textes
Unter Berücksichtigung der benutzerseitig vorgegebenen Randbedingungen können sehr viele Kombinationen von Schriftarten und Auszeichnungsformen gewählt werden. Der Anwender kann nach seinem Belieben jede davon auswählen. Von diesen Kombinationen sollten eine Reihe nicht gewählt werden, da sie nicht für den Zweck und die beabsichtigte Wirkung geeignet sind.
Darüber hinaus fallen einige heraus, weil sie den primären ästhetischen Ansprüchen nicht genügen.
Die endgültig ausgewählte Schriftart ergibt sich aus den Schriftarteigenschaften, die zueinander passen und vom Anwender gewünscht werden. Ein Ästhetik-Faktor sollte nun verschiedene Schriftarteigenschaften zu einem Wert zusammenfassen, damit diese in ihrer Gesamtheit verglichen werden können.
Als Lösung bietet sich unmittelbar die Konstruktion (Design) einer Schriftart mit den dazugehörigen Eigenschaften an, die anschließend mit vordefinierten Layouts verglichen wird, die von Experten mit entsprechenden Werten versehen worden sind. Diese vordefinierten Werte können als Ästhetik-Faktoren bezeichnet werden, denn sie geben an, inwieweit bestimmte, kombiniert auftretende Schriftarteigenschaften innerhalb eines Textes mit einem bestimmten ästhetischen Reiz verwendet werden dürfen. Als Beispiel sei dazu angegeben, daß durchaus sowohl die Schriftart Helvetic als auch der Schriftmodus "fixed" verwendet werden können. Beide jedoch zusammen zu verwenden, würde ein nicht sehr schönes Schriftbild und somit einen niedrigen Ästhetik-Faktor ergeben. Man kann dann den Ästhetik-Faktor als denjenigen ästhetischen Wert verstehen, den ein Layout besitzt: Um ein Layout zu bekommen, das höchsten ästhetischen Ansprüchen genügt, müssen alle vordefinierten Layoutbedingungen, einschließlich derjenigen mit den höchsten Ästhetik-Faktoren, berücksichtigt werden. Von diesen Layoutbedingungen kann dann stückchenweise (mit absteigendem Ästhetik-Faktor) abgewichen werden, falls das berechnete Layout dem Anwender nicht gefällt oder aber kein entsprechendes Layout berechnet werden konnte.
Durch eine andere Repräsentation können diese vordefinierten Layoutformen als Menge von Regeln, die dann nur einzelne Schriftarteigenschaften betreffen, implementiert werden. Daher ist es vielleicht besser, anstatt von einem Ästhetik-Faktor von einem Ästhetik-Wert (dieser Begriff wird von jetzt an benutzt) zu sprechen, den bestimmte Kombinationen von Schriftarteigenschaften besitzen.
Die Regeln, die einen derartigen Ästhetik-Wert berücksichtigen, könnten dann folgenden Aufbau besitzen:
regel ([<ID-Nr>,] <Bedingung>, <Ästhetik-Wert>).
Dieser Regelaufbau wird in den nachfolgenden Abschnitten, die sich mit den Regelparametern beschäftigen, weiter verfeinert und verifiziert.
3.4.1 Die Wertematrix
Die aktuell ausgewählte Kombination von Schriftarten, Auszeichnungsformen, usw. kann in Form einer Matrix dargestellt werden.
Folgende Parameter existieren, um das Schriftbild eines Textes festzulegen:
Schriftart
Schriftgröße
Zeilenabstand
Verfettung
Kursivität
Proportionalität
Diese Textparameter ergeben zusammen mit den Formaten, auf die die Parameter jeweils getrennt angewendet werden können, eine Tabelle (Matrix), deren Elemente die äußere Form eines Textes bestimmen:
Grundschrift
Titel 1. Stufe
Titel 2. Stufe
..
Titel n. Stufe
Auszeichnung
Schlagwort
Fußnote
Marginalie
Zitat
Die Regeln greifen einzelne Einträge dieser Matrix auf und überprüfen deren Werte im Verhältnis zueinander: Beispielsweise muß der Zeilenabstand immer größer als die Schriftgröße - innerhalb eines Formats - sein.
Darüber hinaus existieren noch Formatangaben, die die Größe des Blatt Papiers und den Satzspiegel bestimmen, aber nicht in dieser Matrix enthalten sind, sondern getrennt über einen einfachen Algorithmus berechnet werden, auf den aber nicht näher eingegangen wird.
3.4.2 Der Ästhetik-Wert
Der Ästhetik-Wert gibt den Wert an, den eine Layoutform besitzt, falls die zugeordnete Bedingung (s.u.) zutrifft. Das einfachste Verfahren zur Herleitung eines möglichst ästhetischen Layouts führt iterativ über die Berücksichtigung einzelner Regeln mit ansteigendem Ästhetik-Wert. Es müssen alle Bedingungen zutreffen, deren zugeordneter Ästhetik-Wert unterhalb des resultierenden Gesamt-Ästhetik-Wertes (s.u.) liegt: Eine Bedingung, die immer gelten muß, um einen hohen Gesamt-Ästhetik-Wert zu erreichen, muß einen hohen Ästhetik-Wert besitzen. Es ist dann nicht mehr schwierig, eine Inferenzmaschine für eine derartig aufgebaute Regelmenge zu konstruieren.
3.4.3 Die Bedingung
Wenn die Bedingung zutrifft, kann der Ästhetik-Wert zur Berechnung des Gesamt-Ästhetik-Wertes (s.u.) herangezogen werden.
Die Bedingung kann für eine Vereinfachung der Abarbeitung und Steigerung der Leistungsfähigkeit noch weiter in eine Vor- und Hauptbedingung unterteilt werden. Ein Test auf Zutreffen der Hauptbedingung und damit auf Erfüllung der Gesamtbedingung wird nur dann durchgeführt, wenn die Vorbedingung erfüllt ist. Sollte die Vorbedingung nicht erfüllt werden, so ist dennoch die gesamte Bedingung erfüllt:
<Bedingung> ::= <Vorbedingung>, <Hauptbedingung>
Auf diese Weise kann eine differenziertere Untersuchung der gewählten Layoutform stattfinden, da Regeln existieren, die nur unter bestimmten Bedingungen getestet oder erfüllt werden können. So ist z.B. ein bestimmter weiterführender Test von Schriftarteigenschaften nur notwendig, wenn vom Anwender bestimmte Wirkungen beabsichtigt sind. Ohne eine derartige Unterteilung entstehen je nach beabsichtigter Wirkung unterschiedliche Gesamt-Ästhetik-Werte, da sich der Gesamt-Ästhetik-Wert - unter der Voraussetzung, daß eine bestimmte Wirkung eingegeben worden ist - nur dann erhöht, wenn die gesamte Bedingung erfüllt ist. Diese Unterteilung der Bedingung ergibt nun einen gleichmäßig hohen Gesamt-Ästhetik-Wert, weil sich dieser auch bei nicht eingegebener Wirkung entsprechend erhöht.
3.4.4 Die Identifikationsnummer
Als dritter Parameter sollte noch eine Identifikationsnummer für eine leichte Identifizierung der einzelnen Regeln aufgenommen werden. Dies kann z.B. die Wissensakquisition, die Gruppierung von Regeln oder die Zuordnung von erläuternden Texten für die Erklärungskomponente beträchtlich erleichtern.
Wie später beschrieben wird, dient die Identifikationsnummer ebenfalls als Referenz zur Angabe bestimmter Implikationen (s.u.) der einzelnen Regeln untereinander und ist damit doch unentbehrlich: Die Identifikationsnummer ist so zu wählen, daß sie eine eindeutige Identifikation jeder Regel gestattet.
Bei einer Erweiterung des Systems kann die Identifikationsnummer zur Sperrung einzelner Regeln für bestimmte Dokumentenklassen verwendet werden, wenn sich dies als vorteilhaft erweisen sollte.
Darüber hinaus wäre eine Sperrung für bestimmte Benutzer(gruppen) denkbar.
3.4.5 Inferenzstrategien
Für die Inferenzkomponente ergeben sich nun bzgl. des oben angegebenen Regelaufbaus mehrere Strategien, nach denen die Regeln abgearbeitet werden können:
- bottom-up: Die Regeln werden mit aufsteigendem Ästhetik-Wert solange abgearbeitet, bis die erste Bedingung nicht mehr zutrifft.
- top-down: Die Abarbeitung erfolgt mit absteigendem Ästhetik-Wert, bis die erste Bedingung zutrifft.
- fixed-ordering: Die einzelnen Regeln stehen zueinander durch eine (Halb-)Ordnung in Relation, die ein Netzwerk möglicher Abarbeitungsfolgen darstellt, das dann durchlaufen wird.
3.4.6 Weitere Regelparameter
Eine weitere Verbesserung des Systemverhaltens ergibt sich, wenn als zusätzlicher Parameter ein Wert aufgenommen wird, der angibt, welcher Systemparameter in welcher Weise geändert werden muß, damit sich das Layout verbessert. Dieser Parameter ist gewissermaßen mit dem Aktionsteil einer Wenn-dann-Regel vergleichbar, nur daß es sich bei dieser "Aktion" um einen Aktionsvorschlag handelt, der vor Ausführung mit anderen Aktionsvorschlägen abgeglichen werden muß. Der Abgleich ist deshalb wichtig, weil durchaus Vorschläge vorhanden sein können, deren Änderungen widersprüchlich sind. In diesem Aktionsvorschlag kann auch eine Angabe enthalten sein, die die Wiederholung einer Regelanwendung (vgl. Kap.3.4.9) fordert. Damit ist es dann möglich, eine Iteration anzugeben, bis bestimmte Einstellungen, die nicht in einem Durchgang der Regelmenge durchgeführt werden können, vorgenommen worden sind.
Dementsprechend kann bei erfüllter Bedingung angegeben werden, welcher Systemparameter sich auf keinen Fall ändern darf, damit sich das bereits erstellte Layout nicht verschlechtert: eine Wertfestlegung.
Welcher Systemparameter sich zuerst ändert, wird von dem Ästhetik-Wert der vorschlagenden Regel abhängig gemacht. In diesem Falle braucht die Inferenzmaschine sich auch nicht mehr um eine spezielle Regelreihenfolge zu kümmern, da jedesmal alle Regeln abgearbeitet werden müssen.
3.4.7 Der Gesamt-Ästhetik-Wert
Als Gesamt-Ästhetik-Wert könnte eines der folgenden Berechnungsmodelle verwendet werden:
- Maximalwert erfüllter Regeln:
Das Erfüllen der Bedingung einer Regel mit einem hohen Wert führt direkt zu einem hohen Gesamt-Ästhetik-Wert. - Minimalwert nicht erfüllter Regeln:
Genau wie unter 1. führt ein niedriger Wert zu einem niedrigen Gesamt-Ästhetik-Wert. - Der durchschnittliche Ästhetik-Wert aller erfüllten Regeln erreicht nie einen vorgegebenen Maximalwert (z.B. 100) und hängt darüber hinaus noch von der Verteilung der Werte der einzelnen Regeln über den gesamten Wertebereich ab.
- Die Differenz aus 1. und 2. ergibt den relativen Abstand von minimal nicht erfüllter und maximal erfüllter Regel an und liefert demnach keinen absoluten Wert.
- Die Combine-Regel nach MYCIN (/Shortliffe 81/ und /Puppe 87/) liefert einen asymptotisch gegen 100 steigenden Gesamt-Ästhetik-Wert.
- Die Summe aus 1. und 2. minus 100 ergibt einen Gesamt-Ästhetik-Wert aus dem Bereich von -100 bis +100.
Darüber hinaus wird wie bei allen vorhergehenden Berechnungsmodellen die Anzahl der erfüllten Regeln nicht berücksichtigt. - Ein Gesamt-Ästhetik-Wert gemäß der prozentualen Anzahl der erfüllten Regeln ergibt eine Gleichbehandlung aller Regeln, wodurch ein direkter Ästhetik-Wert überflüssig ist.
- Bei der Berechnung des Gesamt-Ästhetik-Wertes als Summe der einzelnen Ästhetik-Werte werden alle Regeln berücksichtigt und gemäß ihrem Ästhetik-Wert gewichtet.
Dieser Wert kann zusätzlich auf 100 normiert werden. - Das letzte Berechnungsmodell erfüllt am ehesten die Anforderungen, die an einen Gesamt-Ästhetik-Wert gestellt werden: Der Gesamt-Ästhetik-Wert sollte verschiedene Layoutformen über einen einzelnen Wert miteinander vergleichbar machen. Nach diesem Berechnungsmodell wird jede erfüllte Regel nach ihrem Ästhetik-Wert gewichtet in die Rechnung mit einbezogen.
3.4.8 Der Testwert
Durch eine weitere Unterteilung des Ästhetik-Wertes läßt sich eine differenziertere Bearbeitung erreichen:
<Ästhetik-Wert> ::= <Testwert>, <tatsächl. Ästhetik-Wert>
Der Testwert dient dazu, eine Reihenfolge für die Abarbeitung der Regeln ohne Änderung des tatsächlichen Ästhetik-Wertes herzustellen: Diejenigen Regeln, die einen hohen Testwert besitzen, werden zuerst untersucht, unabhängig davon, welchen tatsächlichen Ästhetik-Wert sie besitzen. Dieser Testwert erlaubt es, wichtige Tests, die z.B. druckerspezifisch sind, vorwegzunehmen, ohne den tatsächlichen Ästhetik-Wert anzuheben. Auf Grund dieses Schemas ergibt sich ein fixed-ordering-Verfahren (s. Kap. 3.4.5), dessen Abarbeitungsreihenfolge durch den Testwert bestimmt wird.
3.4.9 Regelimplikationen
Einige Regeln sind unmittelbar voneinander abhängig, ohne daß sie als eine einzige Regel formuliert werden könnten bzw. sollten. Dazu gehört z.B. eine wiederholte Vergrößerung des Zeilenabstandes (es gibt mehrere verschiedene Regeln dafür), wenn durch eine Regel (Antezedent) die Schriftgröße vergrößert worden ist: Nachdem die Regeln für die Schriftgröße erfolgreich angewendet worden sind, muß die Regel für den Zeilenabstand (Implikant) angewendet werden.
Durch eine Implikation können die einzelnen Regeln wesentlich einfacher formuliert werden, wenn deren gegenseitige Abhängigkeit (s. Kap. 3.3.2) bekannt ist.
Als zusätzliche Einschränkung muß für einen vereinfachten Inferenzprozeß verlangt werden, daß der Testwert der abhängigen Regel kleiner als der Testwert des Antezedenten ist: Diese Einschränkung ist notwendig, damit die Regel des Implikanten nach der Regel des Antezedenten getestet wird, weil die verbleibenden Regeln nach deren Testwert absteigend sortiert werden. Der Inferenzprozeß wartet ab, bis der Antezedent erfüllt worden ist oder gar nicht mehr erfüllt werden kann, und versucht erst dann den Implikanten zu erfüllen. Der Nachteil dieses Verfahrens liegt in der "Sequentialisierung" der Ausführung der Änderungsvorschläge von Antezedent und Implikant und damit in einer zu hohen Anzahl von Schleifendurchläufen, obwohl häufig, wie in dem Beispiel mit Schriftgröße und Zeilenabstand, die Änderungen in die gleiche Richtung laufen und daher "parallelisiert" werden könnten. Unter der zusätzlichen Einschränkung, daß keine gegenteiligen Änderungen von Antezedent und Implikant vorgeschlagen werden, kann eine "parallele" Verarbeitung stattfinden.
3.4.10 Der endgültige Regelaufbau
Zusammenfassend läßt sich somit der Regelaufbau wie folgt in PROLOG-Notation darstellen:
regel(
<Regelnummer>,
<Unifikationsparameter>,
<Vorbedingung>,
<Hauptbedingung>,
<Änderungsvorschläge und Regelwiederholungen>,
<Wertfestlegung>,
<Testwert>,
<tatsächlicher Ästhetikwert>
).
Der Unifikationsparameter ist nur vorhanden, weil PROLOG keine globalen Variablen kennt und deshalb die aktuelle Werteinstellung der Matrix als Parameter zu Unifikationszwecken mit übergeben bekommen muß.
3.4.11 Beispiel einer Regel
Damit der Aufbau der Regeln etwas deutlicher wird, soll dies anhand zweier Beispiele noch eingehender erläutert werden:
Beispiel 1:
regel(
1,
Liste,
[get-tabelle(Liste, grundschrift, schriftart, courier)],
[get-tabelle(Liste, grundschrift, schriftgröße, 12)],
[[X1, schriftgröße, 12],
[test-again, [8, 401]]],
[[X2, schriftgröße]],
100,
0
).
Diese Regel dient nur dazu, falls es sich bei der Schriftart um Courier handelt, die Schriftgröße auf 12 Punkt zu setzen, weil der Laserdrucker diese Schriftart nur in dieser Größe drucken kann. Damit diese Regel auf jeden Fall angewendet wird, bekommt sie einen sehr hohen Testwert (100). Da in diesem Fall durch eine derartige Änderung sich nichts an dem ästhetischen Wert des Layouts ändert, ist der Ästhetik-Wert auf Null gesetzt worden. Die Regel Nr. 8 bzw. Nr. 401 berechnet den Zeilenabstand neu (test-again), nachdem die Schriftgröße geändert worden ist.
Beispiel 2:
regel(
402,
Liste,
[angaben(wirkung, attribut, kontrastarm)],
[get-tabelle(Liste, grundschrift, verfettung, Fett),
get-tabelle(Liste, auszeichnung, verfettung, Fett)],
[[auszeichnung, verfettung, Fett]],
[],
10,
10
).
Die Regel aus Beispiel 2 wird dazu benutzt, eine kontrastarme Auszeichnung auszusuchen, d.h. für eine Auszeichnung darf nur die Art der Verfettung verwendet werden, die schon in der Grundschrift eingestellt ist. Diese Regel reicht aber allein noch nicht aus, um eine Auszeichnungsform zu wählen.
3.4.12 Erklärungskomponente für die Typographie
Im Gegensatz zur Erklärungskomponente für den Schriftsatz besteht die Erklärungskomponente für die Typographie in einer natürlichsprachlichen Aufbereitung der Regeln, die aufgrund der Benutzerangaben verwendet werden konnten. Da die Regeln alle den gleichen Aufbau besitzen und bekannt ist, welche Prädikate zur Formulierung der jeweiligen Bedingung (s.o.) verwendet werden, läßt sich eine Regelmenge konstruieren, die diese Umsetzung in die natürliche Sprache (z.B. anhand von Schablonen) vornimmt.
3.4.13 Der Inferenzprozeß
Der Inferenzprozeß insgesamt läßt sich in Form eines Nassi-Schneidermann-Diagramms folgendermaßen veranschaulichen:
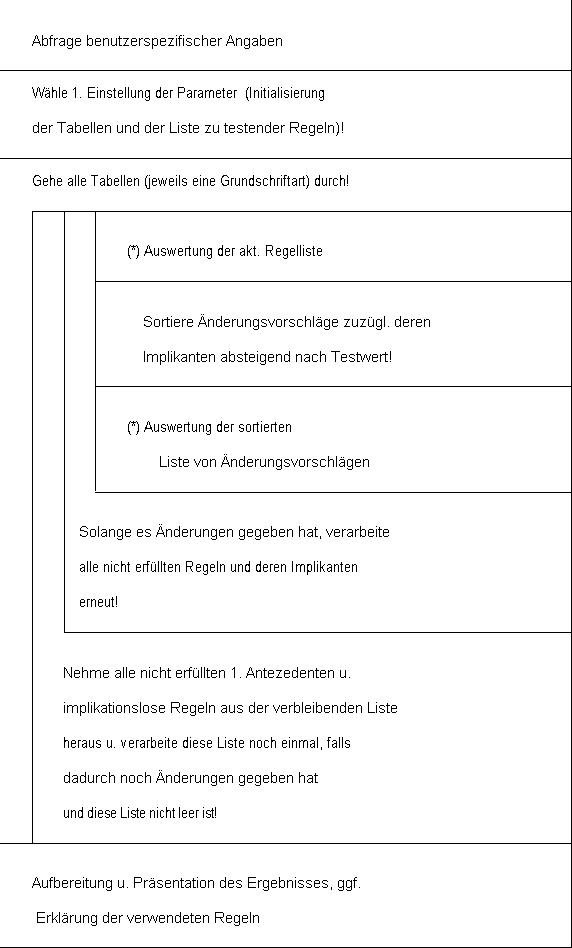
Abb. 3.20: Inferenzmaschine
Die beiden wichtigsten Teile dieses Diagramms (*) sind auf den folgenden Seiten noch einmal vergrößert dargestellt.
3.4.13.1 Auswertung der aktuellen Regelliste
Das erste Teildiagramm beschreibt den Algorithmus, der für die Auswertung der einzelnen Regeln benutzt wird:
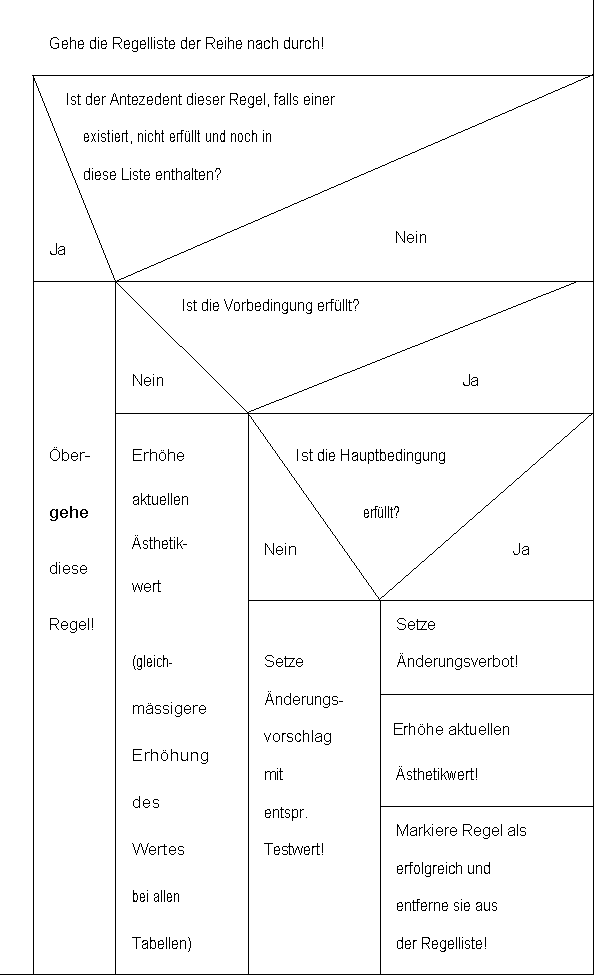
Abb. 3.21: Auswertung der aktuellen Regelliste
Die absteigend nach dem zugehörigen Testwert sortierten Regeln werden der Reihe nach ausgewertet, sofern bei einem vorhandenen Antezedenten auch dessen Bedingung erfüllt ist. Wenn die Vorbedingung erfüllt ist, d.h. eine Anwendung dieser Regel möglich ist, werden die zugeordneten Hauptbedingungen untersucht, ansonsten wird der Gesamt-Ästhetik-Wert um den angegebenen Ästhetik-Wert hochgezählt. Wenn die Hauptbedingung nicht erfüllt werden kann, wird ein Änderungsvorschlag mit dem zugeordneten Testwert gespeichert. Bei einer erfolgreichen Anwendung der Gesamtbedingung wird ein Änderungsverbot, eine Erhöhung des Gesamt-Ästhetik-Wertes und eine Markierung dieser Regel als erfolgreich bewirkt.
3.4.13.2 Auswertung der Liste von Änderungsvorschlägen
Das zweite Teildiagramm beschreibt die Auswertung der Liste von Änderungsvorschlägen, die im ersten Teil des Inferenzprozesses erstellt worden ist:
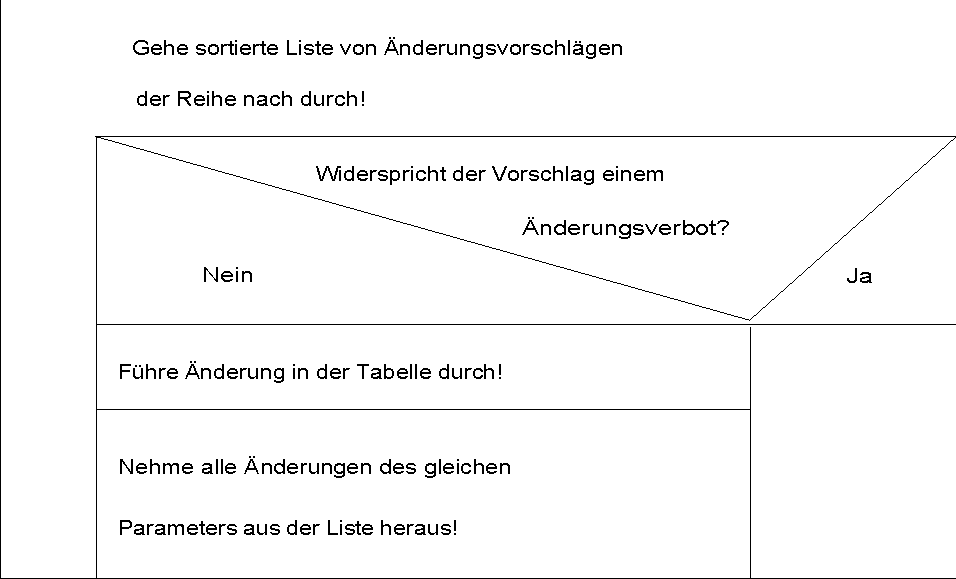
Abb. 3.22: Auswertung der Liste von Änderungsvorschlägen
Die Liste der Änderungsvorschläge wird sequentiell abgearbeitet: Das jeweils erste Element wird aus der Liste herausgenommen und der darin enthaltene Vorschlag wird in die Wertematrix umgesetzt, vorausgesetzt, daß kein Änderungsverbot für dieses Element vorliegt. Danach werden alle anderen Elemente aus der Liste gelöscht, die sich auf den gleichen Matrixeintrag beziehen, damit keine entgegengesetzten Änderungen durchgeführt werden können.
Das Ergebnis der gesamten Berechnung wird dem Benutzer in Form des Gesamt-Ästhetik-Wertes präsentiert, so daß der Benutzer sich daraufhin die zugehörige Matrix ausgeben oder einen kurzen Auszug probeweise ausdrucken lassen kann. Ferner besteht die Möglichkeit, daß die jeweils benutzten Regeln erläutert werden.