| Chapters |
| Schriftsatz |
| Typographie |
| Schlußbemerkungen |
| Literaturhinweise |
| Anhang |
1 Einführung
1.1 "State of the Art"
Textverarbeitungsprogramme unterliegen wie jedes andere Softwarepaket auch einem stetigen Entwicklungsprozeß. Die allerersten Programme benötigten dabei einen Hauptspeicher von nicht einmal 64KB, der heute bei Programmen in der 5. oder aber auch schon 6. Version auf 640KB angewachsen ist. Mit der Programmgröße ist aber auch die Funktionalität angewachsen.
Die Programme zum Verarbeiten der Texte müssen heute in drei große Klassen unterteilt werden. Früher waren es nur die Texteditoren und die Textverarbeitungsprogramme, heute kommen jedoch auch sogenannte DTP-Programme hinzu, die nach dem WYSIWYG-Prinzip arbeiten.
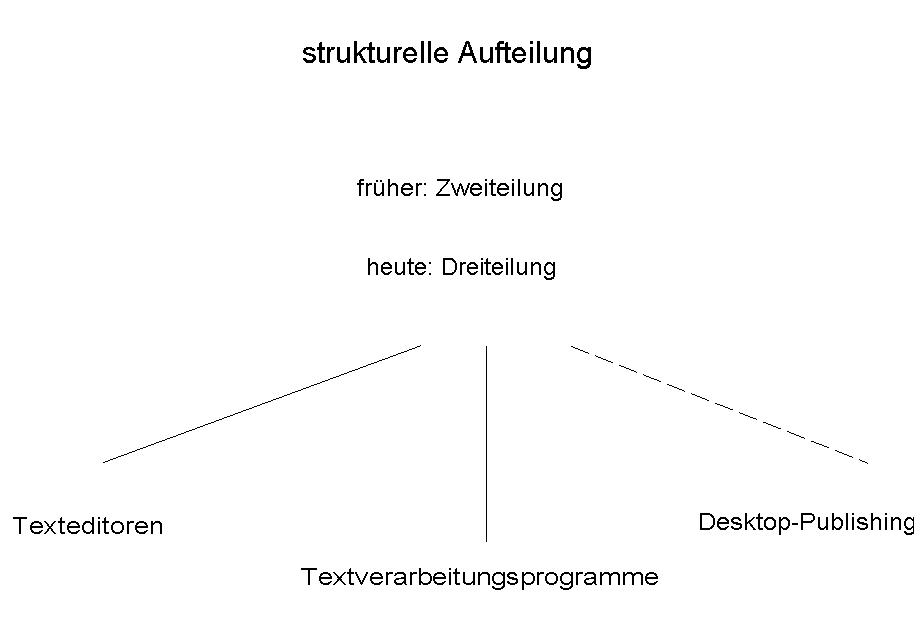
Bei den Texteditoren handelt es sich um Programme, die ASCII-Texte verarbeiten, d.h., sie können keine spezifischen Steuerzeichen lesen bzw. zurückschreiben. Die Texte bestehen aus einer Abfolge von Zeilen, die hauptsächlich die üblichen druckbaren Zeichen und Tabulatoren enthalten. Diese Texte dienen fast ausschließlich dazu, Programmtexte zu erfassen und anschließend von Compilern übersetzen zu lassen.
Die Funktionalität ging ursprünglich von einfachen Kopier-, Verschieb- und Löschfunktionen sowie Laden und Speichern der Texte aus. Heute jedoch sind diese Funktionen oftmals dahingehend erweitert worden, daß sie wesentlich ausgeklügelter sind und nicht nur einfaches Kopieren, sondern auch bspw. zeilenweises, blockweises und/oder zeichenweises Kopieren erlauben. Weiterhin gibt es die Möglichkeit, über einen "Macro-Recorder" ein Macro zu definieren, das der Benutzer bei wiederholtem Gebrauch immer wieder aufrufen kann, um sich dadurch eine bestimmte Tastenfolge zu ersparen. Ebenso gibt es sogenannte "Tag-Files", die es bei einer Menge von Programmdateien ermöglichen, für eine bestimmte Programmiersprache ein Verzeichnis anzulegen, das den Dateinamen und die Zeilennummer enthält, wo der Source-Code einer bestimmte Prozedur/Funktion definiert ist. Auf diese Art und Weise kann der Programmierer während der Programmerstellung auf Tastendruck an die Stelle springen, wo der Programmtext der Funktion, die er gerade benutzen möchte, steht. Dies ist nützlich, um sich schnell einen Überblick darüber zu verschaffen, welche Parameter diese Funktion hat bzw. welche Funktion sie genau erledigt.
Im Gegensatz dazu sind Textverarbeitungsprogramme in der Lage, Texte mit Steuerzeichen abzuspeichern. Das bedeutet, daß sie neben der reinen Textinformation Formatieranweisungen umfassen, die dann schon beim Erfassen und natürlich auch später beim Ausdruck dazu dienen, Schriftarten oder aber Einrückungen und Ähnliches zu bestimmen. Die Dateien, die von diesen Textverarbeitungsprogrammen erzeugt werden, dienen weniger dazu, als Eingabe für Compiler o.ä. verwendet zu werden, sondern Schriftstücke auszudrucken, die später für Briefe, Artikel, Zeitungsanzeigen, Bücher usw. genutzt werden. Bei Verwendung von spezifischen Steuerzeichen wird sofort der große Nachteil ersichtlich, der in der Inkompatibilität der Dateiformate resultiert, so daß verschiedene Textverarbeitungsprogramme Dateien nicht direkt miteinander austauschen können.
Die Textverarbeitungsprogramme müssen noch in zwei Unterklassen unterteilt werden, wobei die eine Klasse die Dialogprogramme umfaßt, d.h. der Benutzer tippt seine Texte in dem richtigen Textverarbeitungsprogramm ein, wobei es durch Funktionsaufrufe über Funktionstasten, Control- oder Escape-Sequenzen gesteuert wird.
Die zweite Klasse arbeitet nach dem Filter-Prinzip, wobei die Texte mit Texteditoren erstellt werden und dann von diesen Filterprogrammen aufbereitet werden, so daß sie auf einem Drucker ein entsprechendes Layout besitzen. Dabei muß erwähnt werden, daß die Steuerzeichen in Form von ASCII-Sequenzen wie z.B. "{new-page}" oder ".pb" für einen festen Seitenumbruch eingegeben und von den Filterprogrammen umgesetzt werden müssen.
Bei der weiteren Betrachtung soll unberücksichtigt bleiben, auf welche Weise die Steuerzeichen eingegeben werden und ob es sich bei den Textverarbeitungsprogrammen um Dialog- oder Filterprogramme handelt.
Wichtig ist jedoch, daß die Textverarbeitungsprogramme verschiedenen Philosophien gehorchen, die konzeptionell unterschiedliche Vorgehensweisen bedingen. Da sei zunächst ein seitenweises Layout erwähnt, d.h., jede Seite wird einzeln eingegeben und ist als getrennte Einheit zu betrachten. Dieser Ansatz wurde damals wegen des zu kleinen Hauptspeicherbereiches entwickelt, hat sich aber in der Praxis nicht bewährt, da es auf diese Art und Weise relativ kompliziert ist, Textteile über das Seitenende hinaus zu verschieben. Diese Aufgabe tritt aber gerade bei der Überarbeitung längerer Textpassagen häufiger auf.
Auf dem freien Markt haben sich zwei andere Konzepte durchgesetzt: Das erste geht davon aus, daß der Text hintereinander weggeschrieben wird, wobei der Benutzer für bestimmte Attribute oder Formate unterschiedliche Steuerzeichen einfügen kann. Beispielsweise kann für eine Auszeichnung eines Wortes das Attribut "unterstrichen" verwendet werden. Dabei bleibt dann unberücksichtigt, welche Schriftart und -größe eingestellt ist. Das zweite Konzept geht davon aus, daß immer eine komplette Beschreibung dessen geben wird, was mit einem bestimmten Textteil gemacht werden soll. Das heißt bei unserem Beispiel der Auszeichnung, daß nicht nur angegeben werden muß, daß sie unterstrichen ist, sondern auch gleichzeitig, daß sie nicht fett, nicht kursiv und nicht gesperrt ist und um welche Schriftart und -größe es sich dabei handelt.
Genau wie bei den Texteditoren hat sich bei den Textverarbeitungsprogrammen die Funktionalität erhöht. So enthält heute jedes Paket neben der Grundfunktionalität, die schon die Texteditoren bereitstellen, mindestens einfache Hilfefunktionen, ein Rechtschreibewörterbuch und einen einfachen Macro-Recorder. Darüber hinaus stellen viele Programme sogenannte Page-Preview-Funktionen zur Verfügung, die es gestatten, den Text ganzseitig in einer Art anzuzeigen, die dem Autor eine Vorstellung von dem endgültigen Aussehen gibt.
Diese erweiterten Funktionen werden in neueren Programmversionen sogar in noch ausgeklügelterer Form angeboten. So ist die Hilfe nicht allein global zu sehen, sondern kontextsensitiv, d.h., daß in einer bestimmten Funktion das Programm weiß, nach welcher Hilfe gefragt ist bzw. der Benutzer das Programm in einer unklaren Situation sogar "fragen" kann, warum es bestimmte Funktionen nicht wie gewünscht ausgeführt hat bzw. welche Funktionstasten der Benutzer hätte drücken müssen, um eine bestimmte Funktion auszuführen.
Ebenso ist das bereitgestellte Wörterbuch nicht nur eine Sammlung von richtig geschriebenen Worten. Es enthält vielmehr einen Thesaurus, so daß in einer bestimmten Situation nach Alternativworten gefragt werden kann, um eine übermäßig hohe Verwendung ein und desselben Wortes zu vermeiden und durch andere, die in diesem Zusammenhang den gleichen Sinn ergeben, zu ersetzen. Weiterhin gibt es Silbentrennmodule, so daß nach Vorwahl einer Sprache eine Silbentrennung mit einer Genauigkeit von über 90% erzielt werden kann. Der Anwender kann im semiautomatischen Modus das Programm durch Verschieben der vorgeschlagenen Trennposition unterstützen bzw. korrigieren.
Bei dem Macro-Editor handelt es sich heute bei einem Textverarbeitungsprogramm nicht mehr nur um einen Macro-Recorder, der eine Sequenz von Tastendrücken aufzeichnet. Vielmehr beinhaltet er erweiterte Funktionen, um die Eingabe von bestimmten Zeichenketten abzufragen oder bestimmte Funktionsaufrufe nur unter bestimmten Bedingungen durchzuführen. Beispielsweise wird bei Briefköpfen nur noch nach dem Datum gefragt und der Rest wird automatisch eingetragen.
Ebenso gehört es heute zum Standard, daß ein Textverarbeitungsprogramm Textbausteine anbietet. Dabei handelt es sich um Textfragmente, die der Benutzer frei editieren und auf Tastendruck zu einem Dokument zusammenladen kann. So werden häufig verwendete Textteile nur einmal erfaßt und stehen dann sofort auf Abruf bereit. Zusammen mit mathematischen Funktionen bilden diese Textbausteine bspw. eine nützliche Unterstützung bei der Erstellung von Angeboten. Das bedeutet, daß der Benutzer auf Knopfdruck bestimmte Angebotselemente selektieren kann, deren Einzelpreis zum Schluß automatisch zu einem Gesamtpreis aufaddiert werden. So kann effizient ein individuelles Angebot erstellt werden.
Die letzte der drei Kategorien sind die Desktop-Publishing-Systeme, von denen es auf dem Markt noch relativ wenige gibt. DTP-Programme lesen Texte, die mit Textverarbeitungsprogrammen oder -editoren erstellt worden sind, ein und stellen diese unter einer graphischen Benutzeroberfläche zu einer Publikation zusammen. DTP-Programme sind auch in der Lage, neben reinen Texten Graphiken, die mit Zeichen- und/oder Malprogrammen erstellt worden sind, einzubinden und zu integrieren. Der Schwerpunkt dieser DTP-Programme liegt in der graphischen Anzeige, so daß der Benutzer eine exakte Vorstellung von dem bekommt, was später auf Papier gedruckt wird. Das entspricht dem Konzept des sog. WYSIWYG-Prinzips: What You See Is What You Get.
Sowohl den Textverarbeitungsprogrammen als auch den DTP-Programmen ist gemeinsam, daß sie Formate, auch Muster oder Styles genannt, unterstützen. Darunter ist die separate Einstellung komplexerer Parameter zu verstehen, so daß an anderen Stellen innerhalb eines Textes auf diese Formate Bezug genommen werden kann. An einem Beispiel ausgedrückt könnte dies bedeuten, daß mehrstufige Titel innerhalb von drei oder vier verschiedenen Formaten definiert werden können, so daß für diese Titel für jede Stufe ein bestimmter Font, eine bestimmte Einrückung, entsprechende Anzahl von Leerzeilen vor oder hinter diesem Titel und gleichzeitig eine Aufnahme in das Inhaltsverzeichnis mit automatischer Kapitelnummerierung zugeordnet werden. Dieses Inhaltsverzeichnis muß nun nur noch im Text an der richtigen Stelle plaziert werden.
Diese vordefinierten Formate werden dann in separaten Dateien abgelegt und es besteht die Möglichkeit, einer Textdatei die richtige Formatdatei zuzuordnen. So ist es problemlos möglich, viele Texte zu editieren, die schematisch und layoutmäßig denselben Aufbau besitzen. Nachträglich ist durch einfache Änderung eines Formates eine einheitliche Änderung im gesamten Text machbar. Bei Softwarepaketen, die dieses Feature nicht besitzen, muß dann für alle vorgenommenen Einstellungen eine Änderung mit einem sehr hohen Arbeitsaufwand durchgeführt werden.
Insgesamt kann jedoch gesagt werden, daß die einzelnen Textverarbeitungsprogramme über eine reichhaltige Ausstattung mit Funktionen verfügen, die aber alle manuell angestoßen werden müssen.
1.2 Motivation und Aufgabenstellung
"Current experimental systems have achieved high levels of performance in consultation tasks like chemical and geological data analysis, computer systems configuration, structural engineering, and even medical diagnosis." (/Barr 81/, S. 9)
Edward A. Feigenbaum
Nach obiger Aussage werden Expertensysteme in den unterschiedlichsten Bereichen, z.T. mit Erfolg, angewendet. Durch diese Aussage wird aber auch deutlich, daß der Bereich der Textverarbeitung bisher komplett übergangen worden ist.
Die intelligente Textverarbeitung ist ein ganz neuer Anwendungsbereich für Expertensysteme!
Bei der Betrachtung bereits existierender Textverarbeitungsprogramme läßt sich feststellen, daß diese sowohl Textbe- als auch -verarbeitungsfunktionen anbieten, mit deren Hilfe der Anwender seinen Text erstellen und verarbeiten kann. Ein Textverarbeitungssystem gibt aber keine Hilfestellung bzgl. der äußeren Form eines Textes. Einen Schritt weiter gehen die modernen Desktop-Publishing-Systeme, die dem Anwender den schon eingegebenen Text nach dem WYSIWYG-Prinzip unter Einbeziehung von Graphik so auf dem Bildschirm präsentieren, wie der Text später auf dem Blatt Papier erscheinen wird.
Beiden Arten von Systemen ist gemeinsam, daß der Anwender die jeweiligen Befehle zur Textgestaltung selbst eingeben muß. Das läuft z.T. sehr komfortabel über Funktionstasten ab, z.T. müssen aber die Steuersequenzen, die der Anwender dann entweder auswendig wissen oder nachschlagen muß, noch mühsam eingegeben werden. Damit der Text in eine Form mit einem ansprechenden Äußeren gebracht werden kann, müssen darüber hinaus grundlegende Regeln des Schriftsatzes und der Typographie eingehalten werden. Diese Regeln sollen, nachdem sie klassifiziert worden sind, als Wissensbasis eines Expertensystems bereitgestellt werden.
"Die für unsere Zwecke vermutlich beste Klassifizierung menschlichen Wissens stammt weder von einem Informatiker noch von einem Psychologen, sondern von einem amerikanischen Anthropologen, E.T. Hall:"
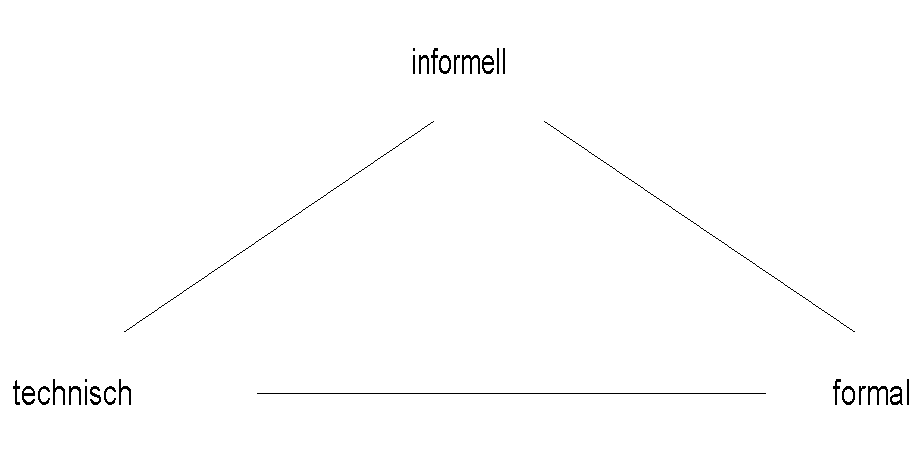
* Das informelle Wissen ist dadurch gekennzeichnet, daß der Mensch es durch "Zuschauen und Nachmachen" erwirbt.
* Das technische Wissen ist in der Regel aus Theorien abgeleitet. Beispiele sind die gesamte Mathematik, physikalische Formeln und technische Rechenverfahren.
* Bei formalem Wissen sind die Regeln nicht numerische "Formeln", sie lassen sich verbal und formal eher in Wenn-dann-Klauseln darstellen."
Informelles Wissen ist nur äußerst schwer in Computern darzustellen und zu verarbeiten. Und auch das technische und formale Wissen ist bei den meisten Menschen und so gut wie allen "Praktikern" eben nicht formal, sondern informell als mehr intuitiv empfundene "Erfahrung" gespeichert.
Gerade bei der Textgestaltung wird aber auf die Intuition, d.h. auf informelles Wissen zurückgegriffen. Für das zu entwickelnde System lassen sich die Regeln auf die folgenden zwei Bereiche aufteilen:
* Die Textaufbereitung nach den Satz- und Korrekturanweisungen für den Schriftsatz (z.B. Gestaltung der Hervorhebungen und Auszeichnungen, Auswahl der Anführungszeichen und Darstellung sprachlicher Eigenschaften (Datumsangaben/ Sonderzeichen)) und
* die Layoutgestaltung nach den Regeln der Typographie (z.B. automatischer Umbruch des Textes unter Vermeidung von Nebeneffekten (wie Hurenkindern und Schusterjungen) und Berücksichtigung von Randbedingungen wie Breite, Höhe, Spaltenanzahl, Minimal- und Maximalangaben des Textes, Wahl einer zu dem Zweck des Schriftstückes passenden Schriftart und -größe, s-Laute/ Ligaturen, Kerning und Silbentrennung nach deutschen Regeln).
1.3 Problemstellung
Innerhalb dieses neuen Anwendungsbereiches wird im Rahmen dieses Buches ein wissensbasiertes System für eine intelligentere Textverarbeitung vorgestellt, wobei die Textverarbeitung dann als intelligent bezeichnet werden soll, wenn sie unter Rückgriff auf linguistisches und/oder typographisches Wissen geschieht. (Häufig wird auch der Begriff des Expertensystems als Synonym für ein wissensbasiertes System verwendet.) Dabei sollen im einzelnen der Bereich der Textaufbereitung nach den Satz- und Korrekturanweisungen für den Schriftsatz sowie die Layoutgestaltung nach den Regeln der Typographie exemplarisch bearbeitet werden. Da dieses System im Hinblick auf einen Einsatz auf einem Personal-Computer entwickelt wird, soll als Implementierungssprache PROLOG benutzt werden, weil die in einem Expertensystem enthaltene Inferenzmaschine schon durch den Resolutions- und Unifikationsprozeß weitestgehend vorgefertigt ist.
Folgende Punkte sollen hier einer Klärung unterzogen werden:
- Ein Teil der Untersuchungen betrifft Überlegungen darüber, die zum Gegenstand haben, welches linguistische Wissen in einem Textverarbeitungssystem enthalten sein kann und welche Probleme bei der Realisierung auftreten (wie z.B. gegenseitige Beeinflussung einzelner Regeln).
- Es muß untersucht werden, ob bereits bestehende Formalismen auf die neue Fragestellung anwendbar sind oder neue entwickelt werden müssen.
- Ein anderer Teil der Arbeit untersucht, welche Parameter zu einem Text erfaßt und wie insbesondere natürlichsprachliche Begriffe in eine Menge von möglichen Layout-Formen übersetzt werden können. Dabei muß eine Lösung für die Tatsache erarbeitet werden, daß sich einzelne Begriffe gegenseitig implizieren, beeinflussen bzw. ausschließen.
- Des weiteren sollen Überlegungen angestellt werden, inwieweit es möglich ist, ästhetische Aspekte in einem wissensbasierten System darzustellen und zu verarbeiten, insbesondere, inwieweit verschiedene Textformen, vielleicht über einen "Ästhetik-Faktor", miteinander verglichen werden können. Dabei sollte dieser Ästhetik-Faktor die verschiedenen Aspekte eines Layouts - wie z.B. Schriftart, Schriftgröße, Zeilenabstand, Länge der Zeilen, Anzahl, Art und Verteilung der Hervorhebungen, Gliederung des Textes und teilende Linien - berücksichtigen. Das Problem liegt dabei konkret in der Erfassung und der ausreichenden Operationalisierung des intuitiv vorhandenen Wissens, damit der Ästhetik-Begriff für einen Computer berechenbar wird.
- Eine wesentliche Randbedingung wird dadurch gestellt, daß dieses System nicht als "reines" Expertensystem gedacht sein kann, das ein fertiges Layout erzeugt, sondern als Beratungssystem das ein Textdokument nach den Regeln des Schriftsatzes und der Typographie und nach den Wünschen des Anwenders gestaltet. Das zu entwickelnde System darf die Kreativität des Benutzers nicht einschränken, sondern nur in bestimmte "erlaubte" Bahnen lenken.
- Da eine Implementierung in PROLOG erfolgen soll und damit ein Interpreter gewählt wird, der in der Lage ist, einen Text effizient zu verarbeiten, soll eine Liste von Mindestanforderungen an diesen erarbeitet werden.
Expertensysteme sind Computerprogramme, die die Fähigkeiten von Experten in einem spezifischen Bereich simulieren sollen. Dazu gehört die Akquisition, Repräsentation, Manipulation und Evaluation von Wissen und Erfahrungen aus dem jeweiligen Anwendungsbereich. Im Gegensatz zu konventionellen (prozeduralen) Programmen benutzen diese Systeme symbolische Logik und Heuristiken bei der Suche nach der Lösung des Problems. In einer sehr engen Beziehung zu Expertensystemen steht die entsprechende Wissensakquisition, d.h. die Fragestellung, wie das Wissen eines Experten im Computer abgebildet (gespeichert) werden kann. Ein weiteres Ergebnis der Arbeit wird daher auch eine Evaluation möglicher Repräsentationsformen für den intendierten Anwendungsbereich sein.
Ein grundlegender Unterschied zu normalen Expertensystemen besteht schon in der anderen Aufteilung des Systems: Für den Schriftsatz gibt es unter Berücksichtigung von benutzerspezifischen Randbedingungen konkret formalisierbare Regeln, die als Teil der Wissensbasis dem System eingegeben werden. Der zweite Teil des Systems beschäftigt sich mit dem Layout, für das es nur intuitiv vorhandene Regeln zur Einschränkung auf ästhetisch anspruchsvolle Formen gibt.
Direkt im Anschluß an diese Einführung folgen zwei Kapitel, die sich mit dem Schriftsatz und dem Layout auseinandersetzen. In beiden Kapiteln werden auf die speziellen Anforderungen, die Probleme, mögliche Wissensrepräsentationsformen und deren jeweilige Verwendbarkeit eingegangen. Das vierte Kapitel faßt die Ergebnisse zusammen und bewertet diese im Hinblick auf eine zukünftige Weiterverwendung. Der Anhang enthält die für das zweite Kapitel wesentlichen Überlegungen.